JavaScript,通常缩写为 JS,是一种解释执行的编程语言。它是现在最流行的脚本语言之一。
JavaScript 是一门基于原型、函数先行的语言,是一门多范式的语言,它支持面向对象编程、命令式编程、函数式编程。
JavaScript 是属于 Web 的语言,它被设计为向 HTML 页面增加交互性。
在客户端,JavaScript 在传统意义上被实现为一种解释语言,但现在已经可以被即时编译(JIT)执行。随着最新的 HTML5 和 CSS3 语言标准的推行,它还可用于游戏、桌面和移动应用程序的开发,以及在服务器端网络环境运行,如 Node.js。
快速入门
alert("Hello World!"); // 第一行 JavaScript 代码
调试
可以使用 Chrome 的开发者工具测试代码。
转到「控制台(Console)」,在这个面板里可以直接输入 JavaScript 代码,按回车后执行。
要查看一个变量的内容,在控制台中输入 console.log(var-name);,回车后显示的值就是变量的内容。
数据类型和变量
数字(number)
JavaScript 不区分整数和浮点数,统一用 number 表示,以下都是合法的 number 类型:
123; // 整数 123
0.456; // 浮点数 0.456
1.2345e3; // 科学计数法表示 1.2345×1000,等同于 1234.5
-99; // 负数
NaN; // NaN 表示 Not a Number。当无法计算结果时用 NaN 表示
Infinity; // Infinity 表示无穷大。当数值超过了 JavaScript 的 Number 所能表示的最大值时,就表示为 Infinity
number 可以直接做四则运算,规则和数学一致:
(1 + 2) * 5 / 2; // 7.5
2 / 0; // Infinity
0 / 0; // NaN
10 % 3; // 1
比较运算符
当对 number 做比较时,可以通过比较运算符得到一个布尔值。实际上,JavaScript 允许对任意数据类型做比较:
false == 0; // true
false === 0; // false
要特别注意相等运算符 ==。JavaScript 在设计时,有两种比较运算符:
-
第一种是
==比较,它会自动转换数据类型再比较。很多时候,会得到非常诡异的结果; -
第二种是
===比较,它不会自动转换数据类型。如果数据类型不一致,返回false;如果一致,再比较。
由于 JavaScript 这个设计缺陷,不要使用 == 比较,应始终坚持使用 === 比较。
另一个例外是 NaN 这个特殊的 number 与所有其他值都不相等,包括它本身:
NaN === NaN; // false
唯一能判断 NaN 的方法是使用 isNaN() 函数:
isNaN(NaN); // true
空(null)和未定义(undefined)
null 表示一个“空”的值,undefined 表示值“未定义”。
在其他语言中,也有类似 JavaScript 的
null的空值,例如 Java 的null、Swift 的nil、Python 的None。
大多数情况下,都应该使用 null,undefined 仅仅在判断函数参数是否传递的情况下有用。
数组(array)
JavaScript 的数组可以包含任意数据类型。例如:
[1, 2, 3.14, "Hello", null, true];
数组的元素可以通过索引来访问:
var arr = [1, 2, 3.14, "Hello", null, true];
arr[0]; // 返回索引为 0 的元素,即 1
arr[5]; // 返回索引为 5 的元素,即 true
arr[6]; // 索引超出了范围,返回 undefined
对象(object)
JavaScript 的对象是一组由键-值组成的无序集合,例如:
var person = {
name: "Bob",
age: 20,
tags: ["js", "web", "mobile"],
city: "Beijing",
hasCar: true,
zipcode: null
};
JavaScript 对象的键都是字符串类型,值可以是任意数据类型。上述 person 对象一共定义了 6 个键值对,其中每个键又称为对象的属性。例如,person 的 name 属性为 "Bob",zipcode 属性为 null。
变量
在 JavaScript 中,使用 var 声明变量。同一个变量可以反复赋值,而且可以是不同类型的值,但是要注意只能声明一次,例如:
var a = 123; // a 的值是整数 123
a = "ABC"; // a 变为字符串 "ABC"
这种变量本身类型不固定的语言称之为动态语言,与之对应的是静态语言。静态语言在定义变量时必须指定变量类型,如果赋值的时候类型不匹配,就会报错。例如 Java 是静态语言,赋值语句如下:
int a = 123; // a 是整数类型变量,类型用 int 声明 a = "ABC"; // 错误:不能把字符串赋给整型变量和静态语言相比,动态语言更灵活,就是这个原因。
要显示变量的内容,可以用 console.log(var-name),打开 Chrome 的控制台就可以看到结果。使用 console.log() 代替 alert() 的好处是可以避免弹出烦人的对话框。
严格模式
JavaScript 在设计之初,为了方便初学者学习,并不强制要求使用 var 声明变量。这个设计错误带来了严重的后果,未使用 var 声明的变量将会被视为全局变量:
i = 10; // i 现在是全局变量
JavaScript 在后来推出了严格模式,强制要求使用 var 声明变量,否则将导致运行错误。
启用严格模式的方法是在 JavaScript 代码的第一行写上:
"use strict";
这是一个字符串,不支持严格模式的浏览器会把它当做一个字符串语句执行,支持严格模式的浏览器将开启严格模式运行 JavaScript。
不用
var声明的变量会被视为全局变量。为了避免这一缺陷,所有的 JavaScript 代码都应该使用严格模式。在后面编写的 JavaScript 代码将全部采用严格模式。
字符串
多行字符串
由于多行字符串用 \n 写起来比较费事,所以 JavaScript 支持一种更简洁的方法——用反引号 `…` 表示。
console.log(`多行
字符串
测试`);
模板字符串
要把多个字符串连接起来,可以用 + 号连接,而在变量很多的时候这样就显得很麻烦。JavaScript 支持一种模板字符串,表示方法同样是使用反引号,但是它会自动替换字符串中的变量:
var name = "小明";
var age = 20;
var message = `你好,${name},你今年 ${age} 岁了!`;
console.log(message);
操作字符串
要获取字符串某个指定位置的字符,使用类似数组的下标操作,索引号从 0 开始。
需要特别注意的是,字符串是不可变的。如果对字符串的某个索引赋值,不会有任何错误,但也没有任何效果:
var s = "Test";
s[0] = "X";
console.log(s); // s 仍然为 "Test"
JavaScript 为字符串提供了一些常用方法。注意,调用这些方法本身不会改变原有字符串的内容,而是返回一个新字符串:
indexOf
indexOf() 会搜索指定字符串出现的位置:
var s = "hello, world";
s.indexOf("world"); // 返回 7,即子串的首字符的位置
s.indexOf("World"); // 没有找到指定的子串,返回 -1
substring
substring() 返回指定索引区间的子串:
var s = "hello, world";
s.substring(0, 5); // 从索引 0 开始到 5(不包括 5),返回 "hello"
s.substring(7); // 从索引 7 开始到结束,返回 "world"
数组
要取得数组的长度,直接访问 length 属性。
需要注意的是,直接给数组的 length 赋一个新的值会导致数组大小的变化:
var arr = [1, 2, 3];
arr.length; // 3
arr.length = 6;
arr; // arr 加长为 [1, 2, 3, undefined, undefined, undefined]
arr.length = 2;
arr; // arr 缩短为 [1, 2]
数组可以通过索引把对应的元素修改为新的值。
同样需要注意的是,如果通过索引赋值时,索引超过了范围,同样会引起数组大小的变化:
var arr = [1, 2, 3];
arr[5] = "x";
arr; // arr 变为 [1, 2, 3, undefined, undefined, "x"]
其它多数编程语言不允许直接改变数组的大小,越界访问索引会报错。然而,JavaScript 的数组却不会有任何错误。在编写代码时,不建议直接修改数组的大小,访问索引时要确保索引不会越界。
数组的方法
slice
slice() 对应于对应字符串中的 substring(),它截取数组的部分元素,然后返回一个新的数组:
var arr = ["A", "B", "C", "D", "E", "F", "G"];
arr.slice(0, 3); // 索引范围 [0, 3): ["A", "B", "C"]
arr.slice(3); // 从索引 3 开始到结束: ["D", "E", "F", "G"]
如果不给 slice() 传递任何参数,就会从头到尾截取所有元素。利用这一点可以很容易地复制一个数组:
var arr = ["A", "B", "C", "D", "E", "F", "G"];
var aCopy = arr.slice();
aCopy; // ["A", "B", "C", "D", "E", "F", "G"]
aCopy === arr; // false
同理,也可以不给字符串的
substring()传递参数以得到复制的字符串:var s = "Hello, World!"; var sCopy = s.substring(); sCopy; // "Hello, World!" sCopy === s; // true
push 和 pop
push() 向数组的末尾添加若干元素,pop() 则删除数组的末元素:
var arr = [1, 2];
arr.push("A", "B"); // 返回数组新的长度: 4
arr; // [1, 2, "A", "B"]
arr.pop(); // pop() 返回 "B"
arr; // [1, 2, "A"]
arr.pop(); arr.pop(); arr.pop(); // 连续 pop 三次
arr; // []
arr.pop(); // 空数组继续 pop 不会报错,而是返回 undefined
arr; // []
unshift 和 shift
unshift() 往数组的头部添加若干元素,shift() 则删除数组的首元素:
var arr = [1, 2];
arr.unshift("A", "B"); // 返回数组新的长度: 4
arr; // ["A", "B", 1, 2]
arr.shift(); // "A"
arr; // ["B", 1, 2]
arr.shift(); arr.shift(); arr.shift(); // 连续 shift 三次
arr; // []
arr.shift(); // 空数组继续 shift 不会报错,而是返回 undefined
arr; // []
sort
sort() 可以对当前数组进行排序,它会直接修改当前数组的元素位置。直接调用时,按照默认顺序排序:
var arr = ["B", "C", "A"];
arr.sort();
arr; // ["A", "B", "C"]
至于按照指定的顺序排序,将会在后面的函数中讲到。
reverse
reverse() 把整个数组的元素反转:
var arr = ["one", "two", "three"];
arr.reverse();
arr; // ["three", "two", "one"]
splice
splice() 是修改数组的“万能方法”,它可以从指定的索引开始删除若干元素,然后再从该位置添加若干元素:
var arr = ["Microsoft", "Apple", "Yahoo", "AOL", "Excite", "Oracle"];
// 从索引 2 开始删除三个元素,然后再添加两个元素:
arr.splice(2, 3, "Google", "Facebook"); // 返回删除的元素 ["Yahoo", "AOL", "Excite"]
arr; // ["Microsoft", "Apple", "Google", "Facebook", "Oracle"]
// 只删除,不添加:
arr.splice(2, 2); // ["Google", "Facebook"]
arr; // ["Microsoft", "Apple", "Oracle"]
// 只添加,不删除:
arr.splice(2, 0, "Google", "Facebook"); // 返回空数组,因为没有删除任何元素
arr; // ["Microsoft", "Apple", "Google", "Facebook", "Oracle"]
concat
concat() 把当前数组和另一个数组连接起来,并返回一个新的数组:
var arr = ["A", "B", "C"];
var added = arr.concat([1, 2, 3]);
added; // ["A", "B", "C", 1, 2, 3]
arr; // ["A", "B", "C"]
实际上,concat() 可以接收任意个元素和数组,并且自动把数组拆开,然后全部添加到新的数组里:
var arr = ["A", "B", "C"];
arr.concat(1, 2, [3, 4]); // ["A", "B", "C", 1, 2, 3, 4]
join
join() 是一个非常实用的方法,它把当前数组的每个元素都用指定的字符串连接起来,然后返回连接后的字符串:
var arr = ["A", "B", "C", 1, 2, 3];
arr.join("-"); // "A-B-C-1-2-3"
如果数组的元素不是字符串,将自动转换为字符串后再连接。
多维数组
如果数组的某个元素又是一个数组,则可以形成多维数组,例如:
var arr = [[1, 2, 3], [400, 500, 600], "-"];
上述数组包含三个元素,其中头两个元素本身也是数组。
对象
JavaScript 的对象是一种无序的集合数据类型,它由若干键值对组成。
访问对象的属性通过 . 操作符完成,但这要求属性名必须是一个有效的变量名。如果属性名包含特殊字符,就必须用引号括起来:
var xiaohong = {
name: "小红",
"middle-school": "No.1 Middle School"
};
xiaohong 的属性名 middle-school 不是一个有效的变量,就需要用引号括起来。访问这个属性也无法使用 . 操作符,必须用 ["xxx"] 来访问:
xiaohong["middle-school"]; // "No.1 Middle School"
xiaohong["name"]; // "小红"
xiaohong.name; // "小红"
在编写 JavaScript 代码的时候,属性名尽量使用标准的变量名,这样就可以直接通过
object.property的形式访问一个属性了。
由于 JavaScript 的对象是动态类型,因此可以自由地给一个对象添加或删除属性:
var xiaoming = {
name: "小明"
};
xiaoming.age; // undefined
xiaoming.age = 18; // 新增一个 age 属性
xiaoming.age; // 18
delete xiaoming.age; // 删除 age 属性
xiaoming.age; // undefined
delete xiaoming["name"]; // 删除 name 属性
xiaoming.name; // undefined
delete xiaoming.school; // 删除一个不存在的 school 属性不会报错
如果要检测 xiaoming 是否拥有某一属性,可以用 in 操作符:
var xiaoming = {
name: "小明",
birth: 1990,
school: "No.1 Middle School",
height: 1.70,
weight: 65,
score: null
};
"name" in xiaoming; // true
"grade" in xiaoming; // false
不过需要注意的是,如果 in 判断一个属性存在,这个属性不一定是 xiaoming 本身的,它可能是 xiaoming 继承得到的:
"toString" in xiaoming; // true
因为 toString 定义在 object 对象中,而所有对象最终都会在原型链上指向 object,所以 xiaoming 也拥有 toString 属性。
要判断一个属性是否是 xiaoming 自身拥有的,而不是继承得到的,可以用 hasOwnProperty() 方法:
var xiaoming = {
name: "小明"
};
xiaoming.hasOwnProperty("name"); // true
xiaoming.hasOwnProperty("toString"); // false
条件判断
在 if (condition) { … } 中,条件逻辑语句 condition 的结果有时不是布尔值。
JavaScript 把 null、undefined、0、NaN 和空字符串 "" 视为 false,其它值一律视为 true。
循环
for … in
for 循环的一个变体是 for … in 循环,它可以把一个对象的所有属性依次循环出来:
var o = {
name: "Jack",
age: 20,
city: "Beijing"
};
for (var key in o) {
console.log(key); // "name","age","city"
}
要过滤掉对象继承的属性,用 hasOwnProperty() 来实现:
var o = {
name: "Jack",
age: 20,
city: "Beijing"
};
for (var key in o) {
if (o.hasOwnProperty(key))
console.log(key); // "name","age","city"
}
由于数组也是对象,而其每个元素的索引被视为对象的属性,因此 for … in 循环可以直接循环出数组的索引:
var a = ["A", "B", "C"];
for (var i in a) {
console.log(i); // "0","1","2"
console.log(a[i]); // "A","B","C"
}
注意,for … in 对数组循环得到的是字符串,而不是 Number。
Map 和 Set
JavaScript 默认的对象表示方式 {} 可以视为其它编程语言中的 Map 或 Dictionary 的数据结构,即一组键值对。
但是 JavaScript 的对象有个小问题,就是键必须是字符串。但实际上 Number 或者其它数据类型作为键也是非常合理的。
为了解决这个问题,JavaScript 引入了新的数据类型 Map。
Map
Map 是一组键值对的结构,具有极快的查找速度。
举个例子,现在要根据学生的名字查找对应的成绩,若用数组实现,需要两个数组:
var names = ["Michael", "Bob", "Tracy"];
var scores = [95, 75, 85];
给定一个名字,要查找对应的成绩,就先要在 names 中找到对应的位置,再从 scores 中取出对应的成绩。数组越长,耗时越长。
若用 Map 实现,只需要一个“名字”-“成绩”的对照表,直接根据名字查找成绩。无论这个表有多大,查找速度都不会慢。实现如下:
var m = new Map([
["Michael", 95],
["Bob", 75],
["Tracy", 85]
]);
m.get("Michael"); // 95
创建 Map 需要一个二维数组,或者直接创建一个空 Map:
var m = new Map();
m.set("Adam", 67); // 添加新的键值对
m.has("Adam"); // 是否存在键「Adam」:true
m.get("Adam"); // 67
m.delete("Adam"); // 删除键「Adam」
m.get("Adam"); // undefined
由于一个键只能对应一个值,所以,多次对一个键放入值,后面的值会替代前面的值:
var m = new Map();
m.set("Adam", 67);
m.set("Adam", 88);
m.get("Adam"); // 88
Set
Set 和 Map 类似,也是一组键的集合,但不存储值。由于键不能重复,所以在 Set 中没有重复的键。
要创建一个 Set,需要提供一个数组作为输入,或者直接创建一个空 Set:
var s1 = new Set(); // 空 Set
var s2 = new Set([1, 2, 3]); // 含 1、2、3
重复元素在 Set 中自动被过滤:
var s = new Set([1, 2, 3, 3, "3"]);
s; // Set {1, 2, 3, "3"}
通过 add(key) 方法可以添加元素到 Set 中,可以重复添加,但不会有效果:
s.add(4);
s; // Set {1, 2, 3, 4}
s.add(4);
s; // 仍然是 Set {1, 2, 3, 4}
通过 delete(key) 方法可以删除元素:
var s = new Set([1, 2, 3]);
s; // Set {1, 2, 3}
s.delete(3);
s; // Set {1, 2}
迭代(iterable)
遍历数组可以采用下标循环,遍历 Map 和 Set 就无法使用下标。为了统一集合类型,引入了新的 iterable 类型,数组、Map 和 Set 都属于 iterable 类型。
具有 iterable 类型的集合可以通过新的 for … of 循环来遍历。
for … in 循环由于历史遗留问题,它遍历的实际上是对象的属性名称。一个数组实际上也是一个对象,它的每个元素的索引被视为一个属性。
当手动给数组添加了额外的属性后,for … in 循环将带来意想不到的意外效果:
var a = ["A", "B", "C"];
a.name = "Hello";
for (var x in a) {
console.log(x); // "0", "1", "2", "name"
}
而这往往不是想要的。
for … of 循环则完全修复了这些问题,它只循环集合本身的元素:
var a = ["A", "B", "C"];
a.name = "Hello";
for (var x of a) {
console.log(x); // "A", "B", "C"
}
然而,更好的方式是直接使用 iterable 内置的 forEach() 方法,它接收一个函数,每次迭代就自动回调该函数。以数组为例:
var a = ["A", "B", "C"];
a.forEach(function (element, index, array) {
// element: 指向当前元素
// index: 指向当前索引
// array: 指向数组本身
console.log("[" + element + ", index = " + index + "]"); // [A, index = 0],[B, index = 1],[C, index = 2]
});
Set 与数组类似,但 Set 没有索引,因此回调函数的前两个参数都是元素本身:
var s = new Set(["A", "B", "C"]);
s.forEach(function (element, sameElement, set) {
console.log(element); // "A","B","C"
});
Map 的回调函数参数依次为值、键和 Map 本身:
var m = new Map([
[1, "x"],
[2, "y"],
[3, "z"]
]);
m.forEach(function (value, key, map) {
console.log(value); // "x","y","z"
});
如果对某些参数不感兴趣,由于 JavaScript 的函数调用不要求参数必须一致,因此可以忽略它们。例如,只需要获得数组的元素:
var a = ["A", "B", "C"];
a.forEach(function (element) {
console.log(element); // "A","B","C"
});
以及获得 Map 的键:
var m = new Map([
["Michael", 95],
["Bob", 75],
["Tracy", 85]
]);
m.forEach(function (value, key) {
console.log(key); // "Michael","Bob","Tracy"
});
函数
函数定义和调用
定义函数
在 JavaScript 中,定义函数的方式如下:
function abs(x) {
if (x >= 0) {
return x;
} else {
return -x;
}
}
如果没有
return语句,函数执行完毕后会返回undefined。
由于 JavaScript 的函数也是一个对象,上述定义的 abs() 函数实际上是一个函数对象,而函数名 abs 可以视为指向该函数的变量。
因此,第二种定义函数的方式如下:
var abs = function (x) {
if (x >= 0) {
return x;
} else {
return -x;
}
};
在这种方式下,function (x) { … } 是一个匿名函数,它没有函数名。但是,这个匿名函数赋值给了变量 abs,所以通过变量 abs 就可以调用该函数。
上述两种定义完全等价,注意第二种方式按照完整语法需要在函数体末尾加一个 ;,表示赋值语句结束。
调用函数
调用函数时,按顺序传入参数即可。
传入的参数比定义的少也没有问题:
abs(); // 返回 NaN
此时 abs(x) 函数的参数 x 将收到 undefined,计算结果为 NaN。
要避免收到 undefined,可以对参数进行检查:
function abs(x) {
if (typeof x !== "number") {
throw "Not a Number";
}
if (x >= 0) {
return x;
} else {
return -x;
}
}
arguments
JavaScript 有一个关键字 arguments,它只在函数内部起作用,并且指向当前函数的调用者传入的所有参数。arguments 类似数组但它不是一个数组:
function foo(x) {
console.log("x = " + x); // 10
for (var i = 0; i < arguments.length; i++) {
console.log("arg " + i + " = " + arguments[i]); // 10, 20, 30
}
}
foo(10, 20, 30);
/*
x = 10
arg 0 = 10
arg 1 = 20
arg 2 = 30
*/
利用 arguments,可以获得调用者传入的所有参数。也就是说,即使函数不定义任何参数,还是可以拿到参数的值:
function abs() {
if (arguments.length === 0) {
return 0;
}
var x = arguments[0];
return x >= 0 ? x : -x;
}
abs(); // 0
abs(10); // 10
abs(-9); // 9
实际上 arguments 最常用于判断传入参数的个数。可能会看到这样的写法:
// foo(a[, b], c)
// 接收 2~3 个参数,b 是可选参数。如果只传两个参数,b 默认为 null:
function foo(a, b, c) {
if (arguments.length === 2) {
// 实际拿到的参数是 a 和 b,c为 undefined
c = b; // 把 b 赋给c
b = null; // b 变为默认值
}
// …
}
rest 参数
由于 JavaScript 函数允许接收任意个参数,于是就不得不用 arguments 来获取所有参数:
function foo(a, b) {
var i, rest = [];
if (arguments.length > 2) {
for (i = 2; i < arguments.length; i++) {
rest.push(arguments[i]);
}
}
console.log("a = " + a);
console.log("b = " + b);
console.log(rest);
}
后来引入了 rest 参数,上面的函数可以改写为:
function foo(a, b, ...rest) {
console.log("a = " + a);
console.log("b = " + b);
console.log(rest);
}
foo(1, 2, 3, 4, 5);
/*
a = 1
b = 2
[ 3, 4, 5 ]
*/
foo(1);
/*
a = 1
b = undefined
[]
*/
rest 参数只能写在最后,前面用 ... 标识。从运行结果可知,传入的参数先绑定 a、b,多余的参数以数组形式交给变量 rest。所以不再需要 arguments 就获取了全部参数。
如果传入的参数连正常定义的参数都没填满,也不要紧,rest 参数会接收一个空数组(注意不是 undefined)。
return 语句
前面讲到了 JavaScript 引擎有一个在行末自动添加分号的机制,这可能会栽到 return 语句的一个大坑:
function foo() {
return { name: "foo" };
}
foo(); // { name: "foo" }
如果把 return 语句拆成两行:
function foo() {
return
{ name: "foo" };
}
foo(); // undefined
需要注意的是,由于 JavaScript 引擎在行末自动添加分号的机制,上面的代码实际上变成了:
function foo() {
return; // 自动添加了分号,相当于 return undefined;
{ name: "foo" }; // 这行语句已经没法执行到了
}
所以正确的多行写法是:
function foo() {
return { // 这里不会自动加分号,因为 { 表示语句尚未结束
name: "foo"
};
}
变量作用域与解构赋值
与其它主流编程语言类似,JavaScript 的函数内变量的作用域为整个函数体,内部函数可以访问外部函数定义的变量。并且在内部函数和外部函数的变量重名时,将“屏蔽”外部函数的变量。
变量提升
JavaScript 在进行函数定义时,会把所有声明的变量“提升”到函数前部:
"use strict";
function foo() {
var x = "Hello, " + y;
console.log(x);
var y = "Bob";
}
foo();
虽然是严格模式,但语句 var x = "Hello, " + y; 并不报错,原因是变量 y 在稍后声明了。但是 console.log 显示 Hello, undefined,说明变量 y 的值为 undefined。这正是因为 JavaScript 引擎自动提升了变量 y 的声明,但没有提升变量 y 的赋值。
对于上述 foo() 函数,JavaScript 引擎看到的代码相当于:
function foo() {
var y; // 提升变量 y 的声明,此时 y 为 undefined
var x = "Hello, " + y;
console.log(x);
y = "Bob";
}
由于 JavaScript 的这一怪异“特性”,在函数内部定义变量时,请严格遵守“在函数内部首先声明所有变量”这一规则。最常见的做法是用一个 var 申明函数内部用到的所有变量:
function foo() {
var
x = 1, // x 初始化为 1
y = x + 1, // y 初始化为 2
z, i; // z 和 i 为 undefined
// 其他语句:
for (i = 0; i < 100; i++) {
// …
}
}
全局作用域
不在任何函数内定义的变量就具有全局作用域。实际上,JavaScript 默认有一个全局对象 window,全局作用域的变量实际上被绑定到 window 的一个属性。
命名空间
全局变量会绑定到 window 上,不同的 JavaScript 文件如果使用了相同的全局变量,或者定义了相同名字的顶层函数,都会造成命名冲突,并且很难被发现。
减少冲突的一个方法是把自己的所有变量和函数全部绑定到一个全局变量中。例如:
// 唯一的全局变量 MYAPP:
var MYAPP = {};
// 其他变量:
MYAPP.name = "myapp";
MYAPP.version = 1.0;
// 其他函数:
MYAPP.foo = function () {
return "foo";
};
把自己的代码全部放入唯一的命名空间 MYAPP 中,会大大减少全局变量冲突的可能。
局部作用域
由于 JavaScript 变量作用域实际上是函数内部,在 for 循环等语句块中无法定义具有局部作用域的变量:
"use strict";
function foo() {
for (var i = 0; i < 100; i++) {
//
}
i += 100; // 仍然可以引用变量 i
}
为了解决块级作用域,引入了新的关键字 let,用 let 替代 var 可以声明一个块级作用域的变量:
"use strict";
function foo() {
var sum = 0;
for (let i = 0; i < 100; i++) {
sum += i;
}
// SyntaxError:
i += 1;
}
常量
使用 const 定义常量,const 与 let 都具有块级作用域。
解构赋值
解构赋值,即同时对一组变量进行赋值。
var [x, y, z] = ["hello", "JavaScript", "ES6"];
// x、y、z 分别被赋值为数组对应元素:
console.log("x = " + x + ", y = " + y + ", z = " + z); // x = hello, y = JavaScript, z = ES6
对数组元素进行解构赋值时,多个变量要用 […] 括起来。
如果数组本身还有嵌套,也可以通过下面的形式进行解构赋值,嵌套层次和位置要保持一致:
let [x, [y, [z]]] = ["hello", ["JavaScript", ["ES6"]]];
x; // "hello"
y; // "JavaScript"
z; // "ES6"
解构赋值还可以忽略某些元素:
let [, , z] = ["hello", "JavaScript", "ES6"]; // 忽略前两个元素,只对 z 赋值第三个元素
z; // "ES6"
如果需要从一个对象中取出若干属性,也可以使用解构赋值,便于快速获取对象的指定属性:
var person = {
name: "小明",
age: 20,
gender: "male",
passport: "G-12345678",
school: "No.4 middle school"
};
var {
name,
age,
passport
} = person;
// name、age、passport 分别被赋值为对应属性:
console.log("name = " + name + ", age = " + age + ", passport = " + passport); // name = 小明, age = 20, passport = "G-12345678"
对一个对象进行解构赋值时,同样可以直接对嵌套的对象属性进行赋值,只要保证对应的层次是一致的:
var person = {
name: "小明",
age: 20,
gender: "male",
passport: "G-12345678",
school: "No.4 middle school",
address: {
city: "Beijing",
street: "No.1 Road",
zipcode: "100001"
}
};
var {
name,
address: {
city,
zip
}
} = person;
name; // "小明"
city; // "Beijing"
zip; // undefined。因为属性名是 zipcode 而不是 zip
// 注意:address 不是变量,而是为了让 city 和 zip 获得嵌套的 address 对象的属性:
address; // Uncaught ReferenceError: address is not defined
使用解构赋值对对象属性进行赋值时,如果对应的属性不存在,变量将被赋值为 undefined,这和引用一个不存在的属性获得 undefined 是一致的。如果要使用的变量名和属性名不一致,可以用下面的语法获取:
var person = {
name: "小明",
age: 20,
gender: "male",
passport: "G-12345678",
school: "No.4 middle school"
};
// 把 passport 属性赋值给变量 id:
let {
name,
passport: id
} = person;
name; // "小明"
id; // "G-12345678"
// 注意:passport 不是变量,而是为了让变量 id 获得 passport 属性:
passport; // Uncaught ReferenceError: passport is not defined
解构赋值还可以使用默认值,这样就避免了不存在的属性返回 undefined 的问题:
var person = {
name: "小明",
age: 20,
gender: "male",
passport: "G-12345678"
};
// 如果 person 对象没有 single 属性,默认赋值为 true:
var {
name,
single = true
} = person;
name; // "小明"
single; // true
有些时候,如果变量已经被声明了,再次赋值的时候,正确的写法也会报语法错误:
// 声明变量:
var x, y;
// 解构赋值:
{
x,
y
} = {
name: "小明",
x: 100,
y: 200
};
// 语法错误:Uncaught SyntaxError: Unexpected token =
这是因为 JavaScript 引擎把 { 开头的语句当作了块处理,于是 = 不再合法。解决方法是用小括号括起来:
({
x,
y
} = {
name: "小明",
x: 100,
y: 200
});
使用场景
解构赋值在很多时候可以大大简化代码。例如,交换两个变量 x 和 y 的值,可以这么写,不再需要临时变量:
var x = 1,
y = 2;
[x, y] = [y, x];
快速获取当前页面的域名和路径:
var {
hostname: domain,
pathname: path
} = location;
如果一个函数接收一个对象作为参数,那么可以使用解构直接把对象的属性绑定到变量中。例如,下面的函数可以快速创建一个 Date 对象:
function buildDate({
year,
month,
day,
hour = 0,
minute = 0,
second = 0
}) {
return new Date(year + "-" + month + "-" + day + " " + hour + ":" + minute + ":" + second);
}
它的方便之处在于传入的对象只需要 year、month 和 day 这三个属性:
buildDate({
year: 2017,
month: 1,
day: 1
});
// Sun Jan 01 2017 00:00:00 GMT+0800 (中国标准时间)
也可以传入 hour、minute 和 second 属性:
buildDate({
year: 2017,
month: 1,
day: 1,
hour: 20,
minute: 15
});
// Sun Jan 01 2017 20:15:00 GMT+0800 (中国标准时间)
方法
在一个对象中绑定函数,称为这个对象的方法。
在严格模式下,会让对象方法的 this 指向 undefined:
"use strict";
var xiaoming = {
name: "小明",
birth: 1990,
age: function () {
var y = new Date().getFullYear();
return y - this.birth;
}
};
xiaoming.age(); // 28
var fn = xiaoming.age;
fn(); // Uncaught TypeError: Cannot read property "birth" of undefined
然而这只是让错误及时暴露出来,并没有解决 this 应该指向的正确位置。
有些时候,会把方法重构一下:
"use strict";
var xiaoming = {
name: "小明",
birth: 1990,
age: function () {
function getAgeFromBirth() {
var y = new Date().getFullYear();
return y - this.birth;
}
return getAgeFromBirth();
}
};
xiaoming.age(); // Uncaught TypeError: Cannot read property "birth" of undefined
上述报错的原因是 this 指针只在 age() 方法的函数内指向 xiaoming。在函数内部定义的函数,this 又指向 undefined 了(在非严格模式下,它重新指向全局对象 window)。
解决办法是用一个 that 变量首先捕获 this,以避免把所有语句都堆到一个方法中:
"use strict";
var xiaoming = {
name: "小明",
birth: 1990,
age: function () {
var that = this; // 在方法内部一开始就捕获 this
function getAgeFromBirth() {
var y = new Date().getFullYear();
return y - that.birth; // 用 that 而不是 this
}
return getAgeFromBirth();
}
};
xiaoming.age(); // 25
apply
要指定函数的 this 指向哪个对象,可以用函数本身的 apply() 方法。它接收两个参数,第一个参数就是需要绑定的 this 变量;第二个参数是数组,表示函数本身的参数。
用 apply() 修复 getAge() 调用:
function getAge() {
var y = new Date().getFullYear();
return y - this.birth;
}
var xiaoming = {
name: "小明",
birth: 1990,
age: getAge
};
xiaoming.age(); // 25
getAge.apply(xiaoming, []); // 25。this 指向 xiaoming,参数为空
另一个与 apply() 类似的方法是 call(),唯一区别是:
-
apply()把参数打包成数组再传入; -
call()把参数按顺序传入。
比如调用 Math.max(3, 5, 4),分别用 apply() 和 call() 实现如下:
Math.max.apply(null, [3, 5, 4]); // 5
Math.max.call(null, 3, 5, 4); // 5
对普通函数调用,通常把
this绑定为null。
装饰器
利用 apply(),还可以动态改变函数的行为。
JavaScript 的所有对象都是动态的。即使是内置的函数,也可以重新指向新的函数。
现在假定想统计一下代码一共调用了多少次 parseInt(),可以把所有的调用都找出来,然后手动加上 count += 1。不过这样做属于笨办法,最佳方案是用自定义的函数替换掉默认的 parseInt():
var count = 0;
var oldParseInt = parseInt; // 保存原函数
window.parseInt = function () {
count += 1;
return oldParseInt.apply(null, arguments); // 调用原函数
};
// 测试:
parseInt("10");
parseInt("20");
parseInt("30");
console.log("count = " + count); // 3
高阶函数
高阶函数指的是接收其它函数作为参数的函数。
function add(x, y, f) {
return f(x) + f(y);
}
var x = add(-5, 6, Math.abs);
console.log(x); // 11
map
举例说明,比如有一个函数 $ f(x)=x^2 $,要把这个函数作用在一个数组 [1, 2, 3, 4, 5, 6, 7, 8, 9] 上,就可以用 map 实现如下:
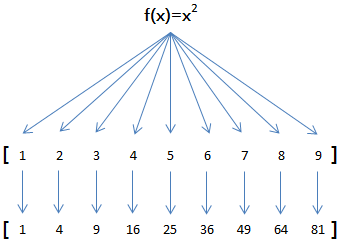
由于 map() 方法定义在 JavaScript 的数组中,调用数组的 map() 方法,传入自定义函数或内置函数,就得到了一个新的数组作为结果:
function pow(x) {
return x * x;
}
var arr = [1, 2, 3, 4, 5, 6, 7, 8, 9];
var results = arr.map(pow);
console.log(results); // [1, 4, 9, 16, 25, 36, 49, 64, 81]
注意:map() 传入的参数是 pow,即函数对象本身。
reduce
数组的 reduce() 把一个函数作用在这个数组的 [x1, x2, x3…] 上,这个函数必须接收两个参数。reduce() 把结果继续和序列的下一个元素做累积计算,其效果就是:
[x1, x2, x3, x4].reduce(f) = f(f(f(x1, x2), x3), x4)
比方说对一个数组求和,就可以用 reduce() 实现:
function add(x, y) {
return x + y;
}
var arr = [1, 3, 5, 7, 9];
var results = arr.reduce(add);
console.log(results); // 25
过滤(filter)
filter 也是一个常用的操作,它用于把数组的某些元素过滤掉,然后返回剩下的元素。
和 map() 类似,数组的 filter() 也接收一个函数。不同的是,filter() 把传入的函数依次作用于每个元素,然后根据返回值是 true 还是 false 决定保留还是丢弃该元素。
例如,在一个数组中,删掉偶数,只保留奇数,可以这么写:
var arr = [1, 2, 4, 5, 6, 9, 10, 15];
var r = arr.filter(function (x) {
return x % 2 !== 0;
});
r; // [1, 5, 9, 15]
例如,把一个数组中的空字符串删掉,可以这么写:
var arr = ["A", "", "B", null, undefined, "C", " "];
var r = arr.filter(function (s) {
return s && s.trim();
});
r; // ["A", "B", "C"]
可见用 filter() 这个高阶函数,关键在于正确实现一个“筛选”函数。
filter() 接收的回调函数,其实可以有多个参数。通常仅使用第一个参数,表示数组的某个元素。回调函数还可以接收另外两个参数,表示元素的位置和数组本身:
var arr = ["A", "B", "C"];
var r = arr.filter(function (element, index, self) {
console.log(element); // 依次打印 "A", "B", "C"
console.log(index); // 依次打印 0, 1, 2
console.log(self); // self 就是变量 arr
return true;
});
利用 filter,可以巧妙地去除数组的重复元素:
var
r,
arr = ["apple", "strawberry", "banana", "pear", "apple", "orange", "orange", "strawberry"];
r = arr.filter(function (element, index, self) {
return self.indexOf(element) === index;
});
去除重复元素依靠的是 indexOf() 总是返回同样元素中的第一个的位置,后续的重复元素位置与 indexOf() 返回的位置不相等,因此被 filter 滤掉了。
排序(sort)
排序也是在程序中经常用到的算法,排序的核心是比较两个元素的大小。
通常规定,对于两个元素 x 和 y:如果认为 x < y,则返回 -1;如果认为 x == y,则返回 0;如果认为 x > y,则返回 1。这样,排序算法就不用关心具体的比较过程,而是根据比较结果直接排序。
JavaScript 数组的 sort() 方法就是用于排序的,但是排序结果可能出乎意料:
// 看上去正常的结果:
["Google", "Apple", "Microsoft"].sort(); // ["Apple", "Google", "Microsoft"];
// apple 排在了最后:
["Google", "apple", "Microsoft"].sort(); // ["Google", "Microsoft", "apple"]
// 无法理解的结果:
[10, 20, 1, 2].sort(); // [1, 10, 2, 20]
第二个排序结果是因为字符串根据 ASCII 码进行排序。
第三个排序结果是因为数组的 sort() 方法默认把所有元素先转换为字符串再排序。
幸运的是,sort() 方法也是一个高阶函数,它还可以接收一个比较函数来实现自定义的排序。
要按数字大小排序,可以这么写:
var arr = [10, 20, 1, 2];
arr.sort(function (x, y) {
if (x < y) return -1;
if (x > y) return 1;
return 0;
});
console.log(arr); // [1, 2, 10, 20]
默认情况下,对字符串排序,是按照 ASCII 的大小比较的。若要忽略大小写,可以先把字符串都转成大写(或者都变成小写),再比较。
需要注意的是,
sort()方法会直接对数组进行修改,它返回的结果仍是当前数组。
从上述例子可以看出,高阶函数的抽象能力是非常强大的,而且核心代码可以保持得非常简洁。
闭包(closure)
函数作为返回值
高阶函数除了可以接受函数作为参数外,还可以把函数作为结果值返回。
接下来实现一个对数组的求和。通常情况下,求和的函数是这样定义的:
function sum(arr) {
return arr.reduce(function (x, y) {
return x + y;
});
}
sum([1, 2, 3, 4, 5]); // 15
但是,如果不需要立即求和,而是在后面的代码中根据需要再计算的话,可以不返回求和的结果,而是返回求和的函数:
function lazy_sum(arr) {
var sum = function () {
return arr.reduce(function (x, y) {
return x + y;
});
}
return sum;
}
当调用 lazy_sum() 时,返回的并不是求和结果,而是求和函数:
var f = lazy_sum([1, 2, 3, 4, 5]); // 函数 sum()
调用函数 f() 时,才真正计算求和的结果:
f(); // 15
在这个例子中,在函数 lazy_sum() 中又定义了函数 sum(),并且内部函数 sum() 可以引用外部函数 lazy_sum() 的参数和局部变量。当 lazy_sum() 返回函数 sum() 时,相关参数和变量都保存在返回的函数中。这种称为“闭包”的程序结构拥有极大的威力。
再注意一点,当调用 lazy_sum() 时,每次调用都会返回一个新的函数,即使传入相同的参数,且调用结果互不影响:
var f1 = lazy_sum([1, 2, 3, 4, 5]);
var f2 = lazy_sum([1, 2, 3, 4, 5]);
f1 === f2; // false
闭包
注意到返回的函数在其定义内部引用了局部变量 arr。所以,当一个函数返回了一个函数后,其内部的局部变量还被新函数引用。所以,闭包用起来简单,实现起来可不容易。
另一个需要注意的问题是,返回的函数并没有立刻执行,而是直到调用了 f() 才执行。看一个例子:
function count() {
var arr = [];
for (var i = 1; i <= 3; i++) {
arr.push(function () {
return i * i;
});
}
return arr;
}
var results = count();
var f1 = results[0];
var f2 = results[1];
var f3 = results[2];
在上面的例子中,每次循环都创建了一个新的函数,然后把创建的三个函数都添加到一个数组中返回了。
可能会认为调用 f1()、f2() 和 f3() 结果应该是 1、4、9,但实际结果是:
f1(); // 16
f2(); // 16
f3(); // 16
全是 16。原因就在于返回的函数引用了变量 i,但它并非立刻执行。等到三个函数都返回时,它们所引用的变量 i 已经变成了 4,因此最终结果为 16。
返回闭包时牢记的一点就是:返回函数不要引用任何循环变量,或者后续会发生变化的变量。
若一定要引用循环变量的话,方法是再创建一个函数,用该函数的参数绑定循环变量当前的值,无论该循环变量后续如何更改,已绑定到函数参数的值不变:
function count() {
var arr = [];
for (var i = 1; i <= 3; i++) {
arr.push((function (n) {
return function () {
return n * n;
}
})(i));
}
return arr;
}
var results = count();
var f1 = results[0];
var f2 = results[1];
var f3 = results[2];
f1(); // 1
f2(); // 4
f3(); // 9
注意这里用了一个“创建一个匿名函数并立刻执行”的语法:
(function (x) {
return x * x;
})(3); // 9
在面向对象的编程语言里,要在对象内部封装一个私有变量,可以用 private 修饰一个成员变量。
在没有 class 机制,只有函数的语言里,借助闭包,同样可以封装一个私有变量。用 JavaScript 创建一个计数器:
"use strict";
function create_counter(initial) {
var x = initial || 0;
return {
inc: function () {
x += 1;
return x;
}
}
}
它用起来像这样:
var c1 = create_counter();
c1.inc(); // 1
c1.inc(); // 2
c1.inc(); // 3
var c2 = create_counter(10);
c2.inc(); // 11
c2.inc(); // 12
c2.inc(); // 13
在返回的对象中,实现了一个闭包,该闭包携带了局部变量 x,并且从外部代码根本无法访问到变量 x。换句话说,闭包就是携带状态的函数,并且它的状态可以完全对外隐藏起来。
闭包还可以把多参数的函数变成单参数的函数。例如,要计算 $ x^y $ 可以用 Math.pow(x, y) 函数。不过考虑到经常计算 $ x^2 $ 或 $ x^3 $,可以利用闭包创建新的函数 pow2() 和 pow3():
"use strict";
function make_pow(n) {
return function (x) {
return Math.pow(x, n);
}
}
// 创建两个新函数:
var pow2 = make_pow(2);
var pow3 = make_pow(3);
console.log(pow2(5)); // 25
console.log(pow3(7)); // 343
箭头函数
JavaScript 中,函数可以用箭头语法(=>)定义,又称“Lambda 表达式”。即用类似于如下的表达式:
x => x * x;
代替:
function (x) {
return x * x;
}
箭头函数相当于匿名函数,并且简化了函数定义。箭头函数有两种格式,一种像上面的,只包含一个表达式,连 { … } 和 return 语句都省略掉了。还有一种可以包含多条语句,这时候就不能省略 { … } 和 return 语句:
x => {
if (x > 0) {
return x * x;
} else {
return -x * x;
}
}
如果参数不是一个,就需要用括号 () 括起来:
// 两个参数:
(x, y) => x * x + y * y;
// 无参数:
() => 3.14;
// 可变参数:
(x, y, ...rest) => {
var i, sum = x + y;
for (i = 0; i < rest.length; i++) {
sum += rest[i];
}
return sum;
}
如果要返回一个对象,就要注意。如果是单表达式,这么写的话会报错:
// SyntaxError:
x => {
foo: x
}
因为和函数体的 { … } 有语法冲突,所以要改为:
x => ({
foo: x
})
this
箭头函数看上去是匿名函数的一种简写,实际上箭头函数和匿名函数有个明显的区别:箭头函数内部的 this 是词法作用域,由上下文确定。
回顾前面的例子,由于 JavaScript 函数对 this 绑定的错误处理,下面的例子无法得到预期结果:
var obj = {
birth: 1990,
getAge: function () {
var b = this.birth; // 1990
var fn = function () {
return new Date().getFullYear() - this.birth; // this 指向 window 或 undefined
};
return fn();
}
};
而箭头函数完全修复了 this 的指向。this 总是指向词法作用域,也就是外层调用者 obj:
var obj = {
birth: 1990,
getAge: function () {
var b = this.birth; // 1990
var fn = () => new Date().getFullYear() - this.birth; // this 指向 obj 对象
return fn();
}
};
obj.getAge(); // 25
如果使用箭头函数,以前的那种 hack 写法:
var that = this;
就不再需要了。
由于 this 在箭头函数中已经按照词法作用域绑定了,所以用 call() 或者 apply() 调用箭头函数时,无法对 this 进行绑定,即传入的第一个参数被忽略:
var obj = {
birth: 1990,
getAge: function (year) {
var b = this.birth; // 1990
var fn = (y) => y - this.birth; // this.birth 仍是 1990
return fn.call({ birth: 2000 }, year);
}
};
obj.getAge(2018); // 28
生成器(generator)
生成器看上去像是函数,但可以返回多次。
一个函数是一段完整的代码,调用一个函数就是传入参数,然后返回结果。函数在执行过程中,如果没有遇到 return 语句(函数末尾如果没有 return,就是隐含的 return undefined;),控制权无法交回被调用的代码。
生成器和函数很像,定义如下:
function* foo(x) {
yield x + 1;
yield x + 2;
return x + 3;
}
生成器和函数不同的是,前者由 function* 定义(注意多出的 * 号),并且除了 return 语句,还可以用 yield 返回多次。
以著名的斐波那契数列为例,它由 0, 1 开头:
0, 1, 1, 2, 3, 5, 8, 13, 21, 34, ...
要编写一个产生斐波那契数列的函数,可以这么写:
function fib(max) {
var
t,
a = 0,
b = 1,
arr = [0, 1];
while (arr.length < max) {
[a, b] = [b, a + b];
arr.push(b);
}
return arr;
}
fib(5); // [0, 1, 1, 2, 3]
fib(10); // [0, 1, 1, 2, 3, 5, 8, 13, 21, 34]
函数只能返回一次,所以必须返回一个数组。但是,如果换成生成器,就可以一次返回一个数,不断返回多次。用生成器改写如下:
function* fib(max) {
var
t,
a = 0,
b = 1,
n = 0;
while (n < max) {
yield a;
[a, b] = [b, a + b];
n++;
}
return;
}
直接调用如下:
fib(5); // fib {[[GeneratorStatus]]: "suspended", [[GeneratorReceiver]]: Window}
直接调用一个生成器和调用函数不一样,fib(5) 仅仅是创建了一个生成器对象,还没有去执行它。
调用生成器对象有两个方法,一是不断地调用生成器对象的 next() 方法:
var f = fib(5);
f.next(); // {value: 0, done: false}
f.next(); // {value: 1, done: false}
f.next(); // {value: 1, done: false}
f.next(); // {value: 2, done: false}
f.next(); // {value: 3, done: false}
f.next(); // {value: undefined, done: true}
next() 方法会执行生成器的代码,然后每次遇到 yield x; 就返回一个对象 {value: x, done: true/false},然后“暂停”。返回的 value 就是 yield 的返回值,done 表示这个生成器是否已经执行结束了。如果 done 为 true,则 value 就是 return 的返回值。
当执行到 done 为 true 时,这个生成器对象就已经全部执行完毕,不要再继续调用 next() 了。
第二个方法是直接用 for … of 循环迭代生成器对象,这种方式不需要自行判断 done:
function* fib(max) {
var
t,
a = 0,
b = 1,
n = 0;
while (n < max) {
yield a;
[a, b] = [b, a + b];
n++;
}
return;
}
for (var x of fib(10)) {
console.log(x); // 依次输出 0, 1, 1, 2, 3, …
}
因为生成器可以在执行过程中多次返回,所以它看上去就像一个可以记住执行状态的函数。利用这一点,写一个生成器就可以实现需要用面向对象才能实现的功能。例如,用一个对象来保存状态,得这么写:
var fib = {
a: 0,
b: 1,
n: 0,
max: 5,
next: function () {
var
r = this.a,
t = this.a + this.b;
this.a = this.b;
this.b = t;
if (this.n < this.max) {
this.n ++;
return r;
} else {
return undefined;
}
}
};
用对象的属性来保存状态,相当繁琐。
生成器还有另一个巨大的好处,就是把异步回调代码变成“同步”代码。这个好处要等到后面学了 AJAX 以后才能体会到。
没有生成器之前,用 AJAX 时需要这么写代码:
ajax("http://url-1", data1, function (err, result) {
if (err) {
return handle(err);
}
ajax("http://url-2", data2, function (err, result) {
if (err) {
return handle(err);
}
ajax("http://url-3", data3, function (err, result) {
if (err) {
return handle(err);
}
return success(result);
});
});
});
回调越多,代码越难看。
有了生成器之后,用 AJAX 时可以这么写:
try {
r1 = yield ajax("http://url-1", data1);
r2 = yield ajax("http://url-2", data2);
r3 = yield ajax("http://url-3", data3);
success(r3);
}
catch (err) {
handle(err);
}
看上去是同步的代码,实际执行是异步的。
标准对象
在 JavaScript 里,一切皆对象。但是这些对象也有不同的类型。为了区分对象的类型,用 typeof 操作符获取对象的类型,它总是返回一个字符串:
typeof 123; // "number"
typeof NaN; // "number"
typeof "str"; // "string"
typeof true; // "boolean"
typeof undefined; // "undefined"
typeof Math.abs; // "function"
typeof null; // "object"
typeof []; // "object"
typeof {}; // "object"
包装对象
除了这些类型外,JavaScript 还提供了包装对象。所谓包装对象,就像 Java 中 int 和 Integer 的关系。
number、boolean 和 string 都有包装对象。包装对象用 new 创建:
var n = new Number(123); // 123,生成了新的包装类型
var b = new Boolean(true); // true,生成了新的包装类型
var s = new String("str"); // "str",生成了新的包装类型
虽然包装对象看上去和原来的值一模一样,显示出来也是一模一样,但类型已经变为 object 了。所以,包装对象和原始值用 === 比较会返回 false:
typeof new Number(123); // "object"
new Number(123) === 123; // false
typeof new Boolean(true); // "object"
new Boolean(true) === true; // false
typeof new String("str"); // "object"
new String("str") === "str"; // false
而在没有写 new 的时候,Number()、Boolean() 和 String() 成为普通函数,把任何类型的数据转换为number、boolean 和 string 类型而不是其包装类型:
var n = Number("123"); // 123,相当于 parseInt() 或 parseFloat()
typeof n; // "number"
var b = Boolean("true"); // true
typeof b; // "boolean"
var b2 = Boolean("false"); // true。"false" 字符串转换结果为 true,因为它是非空字符串
var b3 = Boolean(""); // false
var s = String(123.45); // "123.45"
typeof s; // "string"
总结一下,有这么几条规则:
- 不要使用
new Number()、new Boolean()、new String()创建包装对象; - 用
parseInt()或parseFloat()来转换任意类型到 number; - 用
String()来转换任意类型到 string,或者直接调用某个对象的toString()方法; - 通常不必把任意类型转换为 boolean 再判断,因为可以直接写
if (myVar) {…}; typeof操作符可以判断出 number、boolean、string、function 和 undefined;- 判断数组要使用
Array.isArray(arr); - 判断 null 请使用
myVar === null; - 判断某个全局变量是否存在用
typeof window.myVar === "undefined"; - 函数内部判断某个变量是否存在用
typeof myVar === "undefined"。
此外,还有两点需要注意:
-
null 和 undefined 没有
toString()方法; -
number 对象调用
toString()方法时需要以如下格式:(123).toString(); // "123"
Date
Date 对象表示日期和时间。
要获取系统当前时间,用:
var now = new Date();
now; // Tue Jul 31 2018 20:08:50 GMT+0800 (中国标准时间)
now.getFullYear(); // 2018,年份
now.getMonth(); // 6,月份。注意月份范围是 0~11,6 表示七月
now.getDate(); // 31,表示 31 号
now.getDay(); // 2,表示星期二
now.getHours(); // 20,24 小时制
now.getMinutes(); // 8,分钟
now.getSeconds(); // 50,秒
now.getMilliseconds(); // 245,毫秒数
now.getTime(); // 1533038930245, 以 number 形式表示的时间戳
注意,当前时间是浏览器从本机操作系统获取的时间,所以不一定准确,因为用户可以把当前时间设定为任何值。
时间戳是一个自增的整数,它表示从 1970 年 1 月 1 日零时整的 GMT 时区开始的那一刻,到现在的毫秒数。假设浏览器所在电脑的时间是准确的,那么世界上无论哪个时区的电脑,它们此刻产生的时间戳数字都是一样的。所以,时间戳可以精确地表示一个时刻,并且与时区无关。
如果要创建一个指定日期和时间的 Date 对象,可以用:
var d = new Date(2018, 7, 29, 12, 30, 15, 123);
d; // Sun Jul 29 2018 12:30:15 GMT+0800 (中国标准时间)
需要特别注意的是,JavaScript 的 Date 对象月份值从 0 开始:0 = 1 月,1 = 2 月,……,11 = 12 月。
第二种创建一个指定日期和时间的方法是解析一个符合 ISO 8601 格式的字符串:
var d = new Date("2018-07-29T12:30:15.123+08:00");
d; // 1532838615123
但它返回的不是 Date 对象,而是一个时间戳。不过有时间戳就可以很容易地把它转换为一个 Date:
var d = new Date(1532838615123);
d; // Sun Jul 29 2018 12:30:15 GMT+0800 (中国标准时间)
时区
Date 对象表示的时间总是按浏览器所在时区显示的。不过既可以显示本地时间,也可以显示调整后的 UTC 时间:
var k = new Date(1532838615123);
k.toLocaleString(); // "2018/7/29 下午12:30:15"。本地时间(北京时区 +8:00),显示的字符串与操作系统设定的格式有关
k.toUTCString(); // "Sun, 29 Jul 2018 04:30:15 GMT"。UTC 时间,与本地时间相差 8 小时
时间戳与时区无关。要获取时间戳,可以使用:
Date.now(); // 1533041129055
正则表达式(RegExp)
JavaScript 有两种方式创建一个正则表达式:
第一种方式是直接通过 /正则表达式/ 写出来,第二种方式是通过 new RegExp("正则表达式") 创建一个 RegExp 对象。
两种写法是一样的:
var re1 = /ABC\-001/;
var re2 = new RegExp("ABC\\-001");
re1; // /ABC\-001/
re2; // /ABC\-001/
注意,如果使用第二种写法,因为字符串的转义问题,字符串的两个 \\ 实际上是一个 \。
先看看如何判断正则表达式是否匹配:
var re = /^\d{3}\-\d{3,8}$/;
re.test("010-12345"); // true
re.test("010-1234x"); // false
re.test("010 12345"); // false
RegExp 对象的 test() 方法用于测试给定的字符串是否符合条件。
切分字符串
用正则表达式切分字符串比用固定的字符更灵活。
先看普通的切分代码:
"a b c".split(" "); // ["a", "b", "", "", "c"]
发现无法识别连续的空格。用正则表达式试试:
"a b c".split(/\s+/); // ["a", "b", "c"]
无论多少个空格都可以正常分割。加入 , 试试:
"a,b, c d".split(/[\s\,]+/); // ["a", "b", "c", "d"]
再加入 ; 试试:
"a,b;; c d".split(/[\s\,\;]+/); // ["a", "b", "c", "d"]
实践证明,可以使用正则表达式来把不规范的输入转化成正确的数组。
分组
除了简单地判断是否匹配之外,正则表达式还有提取子串的强大功能。用 () 表示的就是要提取的分组(group)。比如:
^(\d{3})-(\d{3,8})$ 分别定义了两个组,可以直接从匹配的字符串中提取出区号和本地号码:
var re = /^(\d{3})-(\d{3,8})$/;
re.exec("010-12345"); // ["010-12345", "010", "12345"]
re.exec("010 12345"); // null
如果正则表达式中定义了组,就可以在 RegExp 对象上用 exec() 方法提取出子串来:
exec()方法在匹配成功后,会返回一个数组。第一个元素是正则表达式匹配到的整个字符串,后面的字符串表示匹配成功的子串。exec()方法在匹配失败时返回 null。
提取子串非常有用。来看一个更厉害的例子:
var re = /^(0[0-9]|1[0-9]|2[0-3]|[0-9])\:(0[0-9]|1[0-9]|2[0-9]|3[0-9]|4[0-9]|5[0-9]|[0-9])\:(0[0-9]|1[0-9]|2[0-9]|3[0-9]|4[0-9]|5[0-9]|[0-9])$/;
re.exec("19:05:30"); // ["19:05:30", "19", "05", "30"]
这个正则表达式可以直接识别合法的时间。但是有些时候,用正则表达式也无法做到完全验证,比如识别日期:
var re = /^(0[1-9]|1[0-2]|[0-9])-(0[1-9]|1[0-9]|2[0-9]|3[0-1]|[0-9])$/;
对于 "2-30","4-31" 这样的非法日期,用正则还是识别不了,或者说写出来非常困难,这时就需要程序配合识别了。
贪婪匹配
需要特别指出的是,正则匹配默认是贪婪匹配,也就是匹配尽可能多的字符。举例如下,匹配出数字后面的 0:
var re = /^(\d+)(0*)$/;
re.exec("102300"); // ["102300", "102300", ""]
由于 \d+ 采用贪婪匹配,直接把后面的 0 全部匹配了,结果 0* 只能匹配空字符串了。
这时需要让 \d+ 采用非贪婪匹配(也就是尽可能少匹配),才能把后面的 0 匹配出来,加个 ? 就可以让 \d+ 采用非贪婪匹配:
var re = /^(\d+?)(0*)$/;
re.exec("102300"); // ["102300", "1023", "00"]
全局搜索
JavaScript 的正则表达式还有几个特殊的标志,最常用的是 g,表示全局匹配:
var r1 = /test/g;
// 等价于:
var r2 = new RegExp("test", "g");
全局匹配可以多次执行 exec() 方法来搜索一个匹配的字符串。当指定 g 标志后,每次运行 exec(),正则表达式本身会更新 lastIndex 属性,表示上次匹配到的最后索引:
var s = "JavaScript, VBScript, JScript and ECMAScript";
var re = /[a-zA-Z]+Script/g;
// 使用全局匹配:
re.exec(s); // ["JavaScript"]
re.lastIndex; // 10
re.exec(s); // ["VBScript"]
re.lastIndex; // 20
re.exec(s); // ["JScript"]
re.lastIndex; // 29
re.exec(s); // ["ECMAScript"]
re.lastIndex; // 44
re.exec(s); // null,直到结束仍没有匹配到
全局匹配类似搜索,因此不能使用 /^…$/,那样只会最多匹配一次。
正则表达式还可以指定 i 标志,表示忽略大小写;m 标志,表示执行多行匹配。
面向对象编程
与 Java、C# 等不同,JavaScript 不区分类和实例的概念,而是通过原型(prototype)来实现面向对象编程。
假设现在要创建 xiaoming 这个具体的学生。而且有一个现成的 Student 对象:
var Student = {
name: "Robot",
height: 1.2,
run: function () {
console.log(this.name + " is running…");
}
};
那么就直接拿来创建 xiaoming:
var xiaoming = {
name: "小明"
};
Object.setPrototypeOf(xiaoming, Student);
注意最后一行代码把 xiaoming 的原型指向了对象 Student,看上去 xiaoming 仿佛是从 Student 继承下来的:
xiaoming.name; // "小明"
xiaoming.run(); // 小明 is running…
xiaoming 有自己的 name 属性,但并没有定义 run() 方法。不过,由于小明是从 Student 继承而来,只要 Student 有 run() 方法,xiaoming 也可以调用:
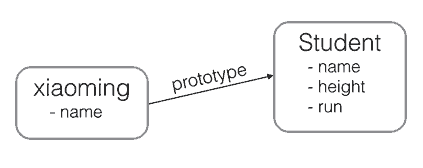
JavaScript 的原型链和 Java、C# 中的类的区别就在于,它没有”类“的概念,所有对象都是实例,所谓继承关系不过是把一个对象的原型指向另一个对象而已。
如果把 xiaoming 的原型指向其他对象:
var Bird = {
fly: function () {
console.log(this.name + " is flying…");
}
};
Object.setPrototypeOf(xiaoming, Bird);
现在 xiaoming 已经无法 run() 了,他已经变成了一只鸟:
xiaoming.fly(); // 小明 is flying…
在 JavaScript 代码运行时期,可以把 xiaoming 从 Student 变成 Bird,或者变成任何对象。
请注意,上述代码仅用于演示目的。在编写 JavaScript 代码时,不要直接用 Object.setPrototypeOf() 去改变一个对象的原型。
Object.create() 方法可以传入一个原型对象,并创建一个基于该原型的新对象,但是新对象什么属性都没有,因此可以编写一个函数来创建 xiaoming:
// 原型对象
var Student = {
name: "Robot",
height: 1.2,
run: function () {
console.log(this.name + " is running…");
}
};
function createStudent(iniName) {
var s = Object.create(Student); // 基于 Student 原型创建一个新对象
s.name = iniName; // 初始化新对象
return s;
}
var xiaoming = createStudent("小明");
xiaoming.run(); // 小明 is running…
Object.getPrototypeOf(xiaoming) === Student;
这是创建原型继承的一种方法,JavaScript 还有其他方法来创建对象。
创建对象
JavaScript 对每个创建的对象都会设置一个原型,指向它的原型对象。
当用 obj.xxx 访问一个对象的属性时,JavaScript 引擎先在当前对象上查找该属性。如果没有找到,就到其原型对象上找;如果还没有找到,就一直上溯到 Object.prototype 对象;最后如果还没有找到,就只能返回 undefined。
例如,创建一个数组对象:
var arr = [1, 2, 3];
其原型链是:
arr --> Array.prototype --> Object.prototype --> null
Array.prototype 定义了 indexOf()、shift() 等方法,因此可以在所有的数组对象上直接调用这些方法。
当创建一个函数时:
function foo() {
return 0;
}
函数也是一个对象,它的原型链是:
foo --> Function.prototype --> Object.prototype --> null
由于 Function.prototype 定义了 apply() 等方法,因此所有函数都可以调用 apply() 方法。
很容易想到,如果原型链很长,那么访问一个对象的属性就会因为花更多的时间查找而变得更慢,因此要注意不要把原型链搞得太长。
构造函数
除了直接用 { … } 创建一个对象外,JavaScript 还可以用一种构造函数的方法来创建对象。它的用法是,先定义一个构造函数:
function Student(name) {
this.name = name;
this.hello = function () {
alert("Hello, " + this.name + "!");
};
}
然后用关键字 new 来调用这个函数,并返回一个对象:
var xiaoming = new Student("小明");
xiaoming.name; // "小明"
xiaoming.hello(); // Hello, 小明!
注意,如果不写 new,这就是一个普通函数,它返回 undefined。但是,如果写了 new,它就变成了一个构造函数,它绑定的 this 指向新创建的对象,并默认返回 this,因此不需要在最后写 return this;。
新创建的 xiaoming 的原型链是:
xiaoming --> Student.prototype --> Object.prototype --> null
也就是说,xiaoming 的原型指向函数 Student 的原型。如果又创建了 xiaohong、xiaojun,那么这些对象的原型与 xiaoming 是一样的:
xiaoming ↘
xiaohong -→ Student.prototype --> Object.prototype --> null
xiaojun ↗
用 new Student() 创建的对象还从原型上获得了一个 constructor 属性,它指向函数 Student 本身:
xiaoming.constructor === Student.prototype.constructor; // true
Student.prototype.constructor === Student; // true
Object.getPrototypeOf(xiaoming) === Student.prototype; // true
xiaoming instanceof Student; // true
上面这些关系可以表示为:
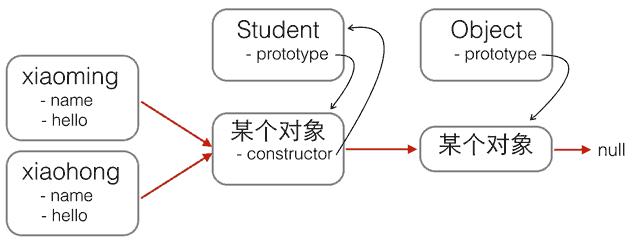
红色箭头是原型链。注意,Student.prototype 指向的对象就是 xiaoming、xiaohong 的原型对象,这个原型对象自己还有个属性 constructor,指向 Student 函数本身。
另外,函数 Student 恰好有个属性 prototype 指向 xiaoming、xiaohong 的原型对象,但是 xiaoming、xiaohong 这些对象可没有 prototype 这个属性,不过可以用 Object.getPrototypeOf() 来查看。
现在就认为 xiaoming、xiaohong 这些对象“继承”自 Student。
注意,xiaoming 和 xiaohong 各自的 hello() 是一个函数,但它们是两个不同的函数,虽然函数名称和代码都是相同的。
如果通过 new Student() 创建了很多对象,这些对象的 hello() 函数实际上只需要共享同一个函数就可以了,这样可以节省很多空间。
要让创建的对象共享一个 hello() 函数,根据对象的属性查找原则,只要把 hello() 函数移动到 xiaoming、xiaohong 这些对象共同的原型上就可以了,也就是 Student.prototype:
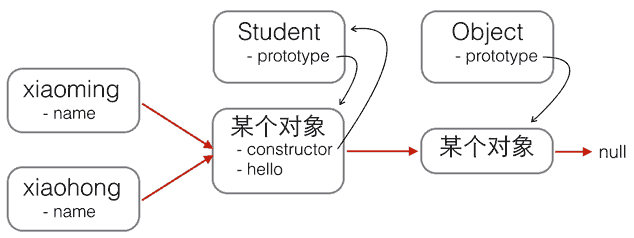
修改代码如下:
function Student(name) {
this.name = name;
}
Student.prototype.hello = function () {
alert("Hello, " + this.name + "!");
};
用 new 创建基于原型的 JavaScript 的对象就是这样。
缺少 new 的构造函数
构造函数在调用时若缺少 new,会出现错误。
如,在严格模式下,this.name = name 将报错,因为 this 绑定为 undefined;在非严格模式下,this.name = name 不报错,因为 this 绑定为 window,于是无意间创建了全局变量 name,并且返回 undefined,这个结果更糟糕。
习惯上,构造函数首字母应当大写,而普通函数首字母应当小写。这样,一些语法检查工具如 JSLint 将可以检测到漏写的 new。
最后,还可以编写一个 createStudent() 函数,在内部封装所有的 new 操作。如下:
function Student(props) {
this.name = props.name || "匿名"; // 默认值为“匿名”
this.grade = props.grade || 1; // 默认值为 1
}
Student.prototype.hello = function () {
alert("Hello, " + this.name + "!");
};
function createStudent(props) {
return new Student(props || {});
}
这个 createStudent() 函数的优点在于:一是不需要 new 来调用;二是参数非常灵活,可以不传,也可以这么传:
var xiaoming = createStudent({
name: "小明"
});
xiaoming.grade; // 1
如果创建的对象有很多属性,只需要传递需要的某些属性,剩下的属性可以用默认值。由于参数是一个 Object,无需记忆参数的顺序。如果恰好从 JSON 拿到了一个对象,就可以直接创建出 xiaoming。
原型继承
在基于类的面向对象编程语言中,继承的本质是扩展一个已有的类,并生成新的派生类。
由于这类语言严格区分类和实例,继承实际上是类型的扩展。但是,JavaScript 由于采用原型继承,无法直接扩展一个类,因为根本不存在类这种类型。
先回顾 Student 构造函数:
function Student(props) {
this.name = props.name || "Unnamed";
}
Student.prototype.hello = function () {
alert("Hello, " + this.name + "!");
};
以及 Student 的原型链:
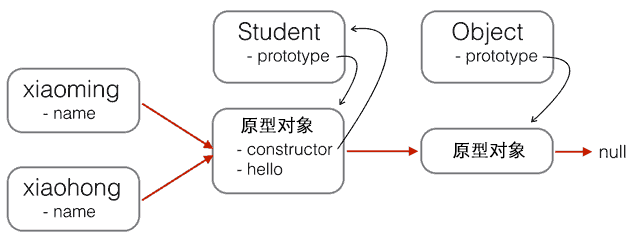
现在,要基于 Student 扩展出 PrimaryStudent,可以先定义出 PrimaryStudent:
function PrimaryStudent(props) {
// 调用 Student 构造函数,绑定 this 变量:
Student.call(this, props);
this.grade = props.grade || 1;
}
但是,调用了 Student 构造函数不等于继承了 Student。PrimaryStudent 创建的对象的原型是:
new PrimaryStudent() --> PrimaryStudent.prototype --> Object.prototype --> null
必须想办法把原型链修改为:
new PrimaryStudent() --> PrimaryStudent.prototype --> Student.prototype --> Object.prototype --> null
这样,原型链对了,继承关系就对了。新的基于 PrimaryStudent 创建的对象不但能调用 PrimaryStudent.prototype 定义的方法,也可以调用 Student.prototype 定义的方法。
对此,可以使用 Object.create() 方法:
PrimaryStudent.prototype = Object.create(Student.prototype);
PrimaryStudent.prototype.constructor = PrimaryStudent;
验证一下:
// 创建 xiaoming
var xiaoming = new PrimaryStudent({
name: "小明",
grade: 2
});
xiaoming.name; // "小明"
xiaoming.grade; // 2
// 验证原型:
Object.getPrototypeOf(xiaoming) === PrimaryStudent.prototype; // true
Object.getPrototypeOf(Object.getPrototypeOf(xiaoming)) === Student.prototype; // true
// 验证继承关系:
xiaoming instanceof PrimaryStudent; // true
xiaoming instanceof Student; // true
class 继承
class 的目的就是让定义类更简单。
先回顾用函数实现 Student 的方法:
function Student(name) {
this.name = name;
}
Student.prototype.hello = function () {
alert("Hello, " + this.name + "!");
};
用 class 来编写,如下:
class Student {
constructor(name) {
this.name = name;
}
hello() {
alert("Hello, " + this.name + "!");
}
}
比较一下就可以发现,class 的定义包含了构造函数 constructor 和定义在原型对象上的函数 hello()(注意没有 function 关键字),这样就避免了 Student.prototype.hello = function () { … } 这样分散的代码。
最后,创建一个 Student 对象的代码则完全一样:
var xiaoming = new Student("小明");
xiaoming.hello();
用 class 定义对象的另一个好处是继承更方便了,直接通过 extends 来实现:
class PrimaryStudent extends Student {
constructor(name, grade) {
super(name); // 记得用 super() 调用基类的构造方法
this.grade = grade;
}
myGrade() {
alert("I am at grade " + this.grade);
}
}
注意 PrimaryStudent 的定义也是 class 实现的,而 extends 则表示原型链对象来自 Student。
派生类的构造方法可能会与基类不太相同。例如,PrimaryStudent 需要 name 和 grade 两个参数,并且需要通过 super(name) 来调用基类的构造函数,否则基类的 name 属性无法正常初始化。
PrimaryStudent 自动获得了基类 Student 的 hello() 方法,其又定义了新的 myGrade() 方法。
需要明确的是,class 仅仅是语法糖,JavaScript 依然是基于原型的。
浏览器
浏览器对象
JavaScript 可以获取浏览器提供的很多对象,并进行操作。
window
window 对象不但充当全局作用域,而且表示浏览器窗口。
window 对象有 innerWidth 和 innerHeight 属性,可以获取浏览器窗口的内部宽度和高度。内部宽高是指除去菜单栏、工具栏、边框等占位元素后,用于显示网页的净宽高,包括滚动条在内。
对应的,还有一个 outerWidth 和 outerHeight 属性,可以获取浏览器窗口的整个宽高。
兼容性:IE8 及以下不支持。
navigator
navigator 对象表示浏览器的信息,最常用的属性包括:
navigator.appName:浏览器名称;navigator.appVersion:浏览器版本;navigator.language:浏览器设置的语言;navigator.platform:操作系统类型;navigator.userAgent:浏览器设定的用户代理字符串。
请注意,navigator 的信息可以很容易地被用户修改,所以 JavaScript 读取的值不一定是正确的。很多初学者为了针对不同浏览器编写不同的代码,喜欢用 if 判断浏览器版本,例如:
var width;
if (getIEVersion(navigator.userAgent) < 9) {
width = document.body.clientWidth;
} else {
width = window.innerWidth;
}
但这样既可能判断不准确,也很难维护代码。正确的方法是充分利用 JavaScript 对不存在属性返回 undefined 的特性,直接用短路运算符 || 计算:
var width = window.innerWidth || document.body.clientWidth;
screen
screen 对象表示屏幕的信息,常用的属性有:
screen.width:屏幕宽度,以像素为单位;screen.height:屏幕高度,以像素为单位;screen.colorDepth:颜色深度,如 8、16、24。根据 CSS 对象模型视图,为兼容起见,该值总为 24。
location
location 对象表示当前页面的 URL 信息。例如,一个完整的 URL:
http://www.example.com:8080/path/index.html?a=1&b=2#TOP
可以用 location.href 获取。要获得 URL 各个部分的值,可以这么写:
location.protocol; // "http"
location.host; // "www.example.com"
location.port; // "8080"
location.pathname; // "/path/index.html"
location.search; // "?a=1&b=2"
location.hash; // "TOP"
要加载一个新页面,可以调用 location.assign()。如果要重新加载当前页面,调用 location.reload() 方法非常方便。
document
document 对象表示当前页面。由于 HTML 在浏览器中以 DOM 形式表示为树形结构,document 对象就是整个 DOM 树的根节点。
document 的 title 属性是从 HTML 文档中的 <title>xxx</title> 读取的,但是可以动态改变。
要查找 DOM 树的某个节点,需要从 document 对象开始查找。最常用的查找是根据 ID 和 Tag Name。
先准备 HTML 数据:
<dl id="drink-menu" style="border:solid 1px #ccc;padding:6px;">
<dt>摩卡</dt>
<dd>热摩卡咖啡</dd>
<dt>酸奶</dt>
<dd>北京老酸奶</dd>
<dt>果汁</dt>
<dd>鲜榨苹果汁</dd>
</dl>
用 document 对象提供的 getElementById() 和 getElementsByTagName() 可以按 ID 获得一个 DOM 节点和按 Tag 名称获得一组 DOM 节点:
var menu = document.getElementById("drink-menu");
var drinks = document.getElementsByTagName("dt");
menu.tagName; // "DL"
var s = "提供的饮料有:";
for (var i = 0; i < drinks.length; i++) {
s += drinks[i].innerHTML;
if (i >= drinks.length - 1) continue;
s += "、";
}
console.log(s);
结果如下:
提供的饮料有:摩卡,酸奶,果汁
document 对象还有一个 cookie 属性,可以获取当前页面的 Cookie。
由于 JavaScript 能读取到页面的 Cookie,而用户的登录信息通常也存在 Cookie 中,这就造成了巨大的安全隐患。为了解决这个问题,服务器在设置 Cookie 时可以使用
httpOnly,设定了httpOnly的 Cookie 将不能被 JavaScript 读取。
操作 DOM
由于 HTML 文档被浏览器解析后就是一棵 DOM 树,要改变 HTML 的结构,就需要通过 JavaScript 来操作 DOM。
始终记住 DOM 是一个树形结构。操作一个 DOM 节点实际上就是这么几个操作:
- 更新:更新该 DOM 节点的内容,相当于更新了该 DOM 节点表示的 HTML 的内容;
- 遍历:遍历该 DOM 节点下的子节点,以便进行进一步操作;
- 添加:在该 DOM 节点下新增一个子节点,相当于动态增加了一个 HTML 节点;
- 删除:将该节点从 HTML 中删除,相当于删掉了该 DOM 节点的内容以及它包含的所有子节点。
在操作一个 DOM 节点前,需要通过各种方式先获取这个 DOM 节点。最常用的方法是 document.getElementById() 和 document.getElementsByTagName(),以及 CSS 选择器 document.getElementsByClassName()。
由于 ID 在 HTML 文档中是唯一的,所以 document.getElementById() 可以直接定位唯一的一个 DOM 节点。document.getElementsByTagName() 和 document.getElementsByClassName()总是返回一组 DOM 节点。要精确地选择 DOM,可以先定位父节点,再从父节点开始选择,以缩小范围。例如:
// 返回 ID 为“test”的节点:
var test = document.getElementById("test");
// 先定位 ID 为“test-table”的节点,再返回其内部所有 tr 节点:
var trs = document.getElementById("test-table").getElementsByTagName("tr");
// 先定位 ID 为“test-div”的节点,再返回其内部所有 class 包含 red 的节点:
var reds = document.getElementById("test-div").getElementsByClassName("red");
// 获取节点 test 下的所有直属子节点:
var cs = test.children;
// 获取节点 test 下第一个、最后一个子节点:
var first = test.firstElementChild;
var last = test.lastElementChild;
第二种方法是使用 querySelector() 和 querySelectorAll(),需要了解 selector 语法,然后使用条件来获取节点,更加方便:
// 通过 querySelector 获取 ID 为 q1 的节点:
var q1 = document.querySelector("#q1");
// 通过 querySelectorAll 获取 q1 节点内的符合条件的所有节点:
var ps = q1.querySelectorAll("div.highlighted > p");
注意,IE8 以下版本不支持
querySelector和querySelectorAll。IE8 仅有限支持。
严格地讲,这里的 DOM 节点是指 Element,但是 DOM 节点实际上是 Node。在 HTML 中,Node 包括Element、Comment、CDATA_SECTION 等很多种,以及根节点 Document 类型。但是,绝大多数时候只关心 Element,也就是实际控制页面结构的 Node,其他类型的 Node 忽略即可。根节点 Document 已经自动绑定为全局变量 document。
更新 DOM
拿到一个 DOM 节点后,可以对它进行更新。
可以直接修改节点的文本,方法有两种。
一种是修改 innerHTML 属性,这个方式非常强大,不但可以修改一个 DOM 节点的文本内容,还可以直接通过 HTML 片段修改 DOM 节点内部的子树:
// 获取 <p id="p-id">…</p>
var p = document.getElementById("p-id");
// 设置文本为 abc:
p.innerHTML = "ABC"; // <p id="p-id">ABC</p>
// 设置 HTML:
p.innerHTML = "ABC <span style=\"color:red\">RED</span> XYZ";
// <p>…</p> 的内部结构已修改
用 innerHTML 时要注意,是否需要写入 HTML。如果写入的字符串是通过网络拿到了,要注意对字符编码来避免 XSS 攻击。
第二种是修改 innerText 或 textContent 属性,这样可以自动对字符串进行 HTML 编码,保证无法设置任何 HTML 标签:
// 获取 <p id="p-id">…</p>
var p = document.getElementById("p-id");
// 设置文本:
p.innerText = "<script>alert(\"Hi\");</script>";
// HTML 被自动编码,无法设置一个 <script> 节点:
// <p id="p-id"><script>alert("Hi");</script></p>
两者的区别在于读取属性时,innerText 不返回隐藏元素的文本,而 textContent 返回所有文本。
另外注意 IE9 以下不支持
textContent。
修改 CSS 也是经常需要的操作。DOM 节点的 style 属性对应所有的 CSS,可以直接获取或设置。
因为 CSS 允许 font-size 这样的名称,但它并非 JavaScript 有效的属性名,所以需要在 JavaScript 中改写为驼峰式命名 fontSize:
// 获取 <p id="p-id">…</p>
var p = document.getElementById("p-id");
// 设置 CSS:
p.style.color = "#ff0000";
p.style.fontSize = "20px";
p.style.paddingTop = "2em";
插入 DOM
当获得了某个 DOM 节点,想在这个 DOM 节点内插入新的 DOM,应该怎么做?
如果这个 DOM 节点是空的,例如 <div></div>,那么直接使用 innerHTML = "<span>child</span>" 就可以修改 DOM 节点的内容,相当于“插入”了新的 DOM 节点。
如果这个 DOM 节点不是空的,那就不能这么做,因为修改 innerHTML 会直接替换掉原来的所有子节点。
有两个办法可以插入新的节点。一个是使用 appendChild(),把一个子节点添加到父节点的最后一个子节点。例如:
<!-- HTML 结构 -->
<p id="js">JavaScript</p>
<div id="list">
<p id="java">Java</p>
<p id="python">Python</p>
<p id="scheme">Scheme</p>
</div>
把 <p id="js">JavaScript</p> 添加到 <div id="list"> 的最后一项:
var
js = document.getElementById("js"),
list = document.getElementById("list");
list.appendChild(js);
现在,HTML 结构变成了这样:
<!-- HTML 结构 -->
<div id="list">
<p id="java">Java</p>
<p id="python">Python</p>
<p id="scheme">Scheme</p>
<p id="js">JavaScript</p>
</div>
因为插入的 js 节点已经存在于当前的文档树,因此这个节点首先会从原先的位置删除,再插入到新的位置。
更多的时候会从零创建一个新的节点,然后追加到指定位置之后:
var
list = document.getElementById("list"),
haskell = document.createElement("p");
haskell.id = "haskell";
haskell.innerText = "Haskell";
list.appendChild(haskell);
这样就动态添加了一个新的节点:
<!-- HTML 结构 -->
<div id="list">
<p id="java">Java</p>
<p id="python">Python</p>
<p id="scheme">Scheme</p>
<p id="haskell">Haskell</p>
</div>
动态创建一个节点然后添加到 DOM 树中,可以实现很多功能。举个例子,下面的代码动态创建了一个 <style> 节点,然后把它添加到 <head> 节点的末尾,这样就动态地给文档添加了新的 CSS 定义:
var d = document.createElement("style");
d.setAttribute("type", "text/css");
d.innerHTML = "p { color: red }";
document.getElementsByTagName("head")[0].appendChild(d);
可以在浏览器的开发者工具中执行上述代码,观察页面样式的变化。
insertBefore
如果要把子节点插入到指定的位置,可以使用 parentElement.insertBefore(newElement, referenceElement);,子节点会插入到 referenceElement 之前。
还是以上面的 HTML 为例,假定要把 Haskell 插入到 Python 之前:
<!-- HTML 结构 -->
<div id="list">
<p id="java">Java</p>
<p id="python">Python</p>
<p id="scheme">Scheme</p>
</div>
可以这么写:
var
list = document.getElementById("list"),
ref = document.getElementById("python"),
haskell = document.createElement("p");
haskell.id = "haskell";
haskell.innerText = "Haskell";
list.insertBefore(haskell, ref);
新的 HTML 结构如下:
<!-- HTML 结构 -->
<div id="list">
<p id="java">Java</p>
<p id="haskell">Haskell</p>
<p id="python">Python</p>
<p id="scheme">Scheme</p>
</div>
可见,使用 insertBefore 的重点是要获得一个“参考子节点”的引用。很多时候,需要循环一个父节点的所有子节点,可以通过迭代children属性实现:
var
i, c,
list = document.getElementById("list");
for (i = 0; i < list.children.length; i++) {
c = list.children[i]; // 获得第 i 个子节点
}
删除 DOM
删除一个 DOM 节点就比插入要容易得多。
要删除一个节点,首先要获得该节点本身以及它的父节点,然后调用父节点的 removeChild() 把自己删掉:
// 获得待删除节点:
var self = document.getElementById("to-be-removed");
// 获得父节点:
var parent = self.parentElement;
// 删除:
var removed = parent.removeChild(self);
removed === self; // true
注意到删除后的节点虽然不在文档树中了,但其实它还在内存中,可以随时再次被添加到别的位置。
当遍历一个父节点的子节点并进行删除操作时,要注意 children 属性是一个只读属性,并且它在子节点变化时会实时更新。
例如,对于如下 HTML 结构:
<div id="parent">
<p>First</p>
<p>Second</p>
</div>
当用如下代码删除子节点时:
var parent = document.getElementById("parent");
parent.removeChild(parent.children[0]);
parent.removeChild(parent.children[1]); // ← 浏览器报错
浏览器报错:parent.children[1] 不是一个有效的节点。原因就在于,当 <p>First</p> 节点被删除后,parent.children 的节点数量已经从 2 变为了 1,索引 [1] 已经不存在了。
因此,删除多个节点时,要注意 children 属性时刻都在变化。
操作表单
用 JavaScript 操作表单和操作 DOM 是类似的,因为表单本身也是 DOM 树。
不过表单的输入框、下拉框等可以接收用户输入,所以用 JavaScript 来操作表单,可以获得用户输入的内容,或者对一个输入框设置新的内容。
HTML 表单的输入控件主要有以下几种:
- 文本框,对应的
<input type="text">,用于输入文本; - 口令框,对应的
<input type="password">,用于输入口令; - 单选框,对应的
<input type="radio">,用于选择一项; - 复选框,对应的
<input type="checkbox">,用于选择多项; - 下拉框,对应的
<select>,用于选择一项; - 隐藏文本,对应的
<input type="hidden">,用户不可见,但表单提交时会把隐藏文本发送到服务器。
获取值
如果获得了一个 <input> 节点的引用,就可以直接调用 value 获得对应的用户输入值:
// <input type="text" id="email">
var input = document.getElementById("email");
input.value; // "用户输入的值"
这种方式可以应用于 text、password、hidden 以及 select。但是,对于单选框和复选框,value 属性返回的是 HTML 预设的值,而需要获得的实际是用户是否“勾上了”选项,所以应该用 checked 判断:
// <label><input type="radio" name="weekday" id="monday" value="1">Monday</label>
// <label><input type="radio" name="weekday" id="tuesday" value="2">Tuesday</label>
var mon = document.getElementById("monday");
var tue = document.getElementById("tuesday");
mon.value; // "1"
tue.value; // "2"
mon.checked; // true 或者 false
tue.checked; // true 或者 false
设置值
设置值和获取值类似,对于 text、password、hidden 以及 select,直接设置 value 就可以:
var input = document.getElementById("email");
input.value = "test@example.com"; // 文本框的内容已更新
对于单选框和复选框,设置 checked 为 true 或 false 即可。
提交表单
方式一是通过 <form> 元素的 submit() 方法提交一个表单。例如,响应一个 <button> 的 click 事件,在 JavaScript 代码中提交表单:
<!-- HTML -->
<form id="test-form">
<input type="text" name="test">
<button type="button" onclick="doSubmitForm()">Submit</button>
</form>
<script>
function doSubmitForm() {
var form = document.getElementById("test-form");
// 可以在此修改 form 的 input…
// 提交 form:
form.submit();
}
</script>
这种方式的缺点是扰乱了浏览器对 form 的正常提交。浏览器默认点击 <button type="submit"> 时提交表单,或者用户在最后一个输入框按回车键。
因此,第二种方式是响应 <form> 本身的 onsubmit 事件,在提交 form 时作修改:
<!-- HTML -->
<form id="test-form" onsubmit="return checkForm()">
<input type="text" name="test">
<button type="submit">Submit</button>
</form>
<script>
function checkForm() {
var form = document.getElementById("test-form");
// 可以在此修改 form 的 input…
// 继续下一步:
return true;
}
</script>
注意要 return true; 来告诉浏览器继续提交。如果 return false;,浏览器将不会继续提交 form,这种情况通常对应于用户输入有误,提示用户错误信息后终止提交 form。
在检查和修改 <input> 时,要充分利用 <input type="hidden"> 来传递数据。例如,很多登录表单希望用户输入用户名和口令,但出于安全考虑,提交表单时不传输明文口令,而是口令的 MD5。普通 JavaScript 开发人员会直接修改 <input>:
<!-- HTML -->
<form id="login-form" method="post" onsubmit="return checkForm()">
<input type="text" id="username" name="username">
<input type="password" id="password" name="password">
<button type="submit">Submit</button>
</form>
<script>
function checkForm() {
var pwd = document.getElementById("password");
// 把用户输入的明文变为 MD5:
pwd.value = toMD5(pwd.value);
// 继续下一步:
return true;
}
</script>
这个做法看上去没什么问题,但用户输入了口令提交时,口令框的显示会突然从几个 * 变成 32 个 *(MD5 有 32 个字符)。要想不改变用户的输入,可以利用 <input type="hidden"> 实现:
<!-- HTML -->
<form id="login-form" method="post" onsubmit="return checkForm()">
<input type="text" id="username" name="username">
<input type="password" id="input-password">
<input type="hidden" id="md5-password" name="password">
<button type="submit">Submit</button>
</form>
<script>
function checkForm() {
var input_pwd = document.getElementById("input-password");
var md5_pwd = document.getElementById("md5-password");
// 把用户输入的明文变为 MD5:
md5_pwd.value = toMD5(input_pwd.value);
// 继续下一步:
return true;
}
</script>
注意到 id 为 md5-password 的 <input> 标记了 name="password",而用户输入的 id 为 input-password 的 <input> 没有 name 属性。没有 name 属性的 <input> 的数据不会被提交。
操作文件
在 HTML 表单中,可以上传文件的唯一控件就是 <input type="file">。
注意:当一个表单包含 <input type="file"> 时,表单的 enctype 必须指定为 multipart/form-data,method 必须指定为 post,浏览器才能正确编码并以 multipart/form-data 格式发送表单的数据。
出于安全考虑,浏览器只允许用户点击 <input type="file"> 来选择本地文件,用 JavaScript 对 <input type="file"> 的 value 赋值是没有任何效果的。当用户选择了上传某个文件后,JavaScript 也无法获得该文件的真实路径。
通常,上传的文件都由后台服务器处理,JavaScript 可以在提交表单时对文件扩展名做检查,以防止用户上传无效格式的文件:
var f = document.getElementById("test-file-upload");
var filename = f.value;
if (!filename || !(filename.endsWith(".jpg") || filename.endsWith(".png") || filename.endsWith(".gif"))) {
alert("Can only upload image file.");
return false;
}
File API
由于 JavaScript 对用户上传的文件操作非常有限,尤其是无法读取文件内容,使得很多需要操作文件的网页不得不用 Flash 这样的第三方插件来实现。
随着 HTML5 的普及,新增的 File API 允许 JavaScript 读取文件内容,获得更多的文件信息。
HTML5 的 File API 提供了 File 和 FileReader 两个主要对象,可以获得文件信息并读取文件。
下面的例子演示了如何读取用户选取的图片文件,并在一个 <div> 中预览图像:
var
fileInput = document.getElementById("test-image-file"),
info = document.getElementById("test-file-info"),
preview = document.getElementById("test-image-preview");
// 监听 change 事件:
fileInput.addEventListener("change", function () {
// 清除背景图片:
preview.style.backgroundImage = "";
// 检查文件是否选择:
if (!fileInput.value) {
info.innerHTML = "没有选择文件";
return;
}
// 获取 File 引用:
var file = fileInput.files[0];
// 获取 File 信息:
info.innerHTML = "文件:" + file.name + "<br>" +
"大小:" + file.size + "<br>" +
"修改:" + file.lastModifiedDate;
if (file.type !== "image/jpeg" && file.type !== "image/png" && file.type !== "image/gif") {
alert("不是有效的图片文件!");
return;
}
// 读取文件:
var reader = new FileReader();
reader.onload = function (e) {
var
data = e.target.result; // "data:image/jpeg;base64,/9j/4AAQSk…(base64编码)…"
preview.style.backgroundImage = "url(" + data + ")";
};
// 以 DataURL 的形式读取文件:
reader.readAsDataURL(file);
});
上面的代码演示了如何通过 HTML5 的 File API 读取文件内容。以 DataURL 的形式读取到的文件是一个字符串,类似于 data:image/jpeg;base64,/9j/4AAQSk…(base64编码)…,常用于设置图像。如果需要服务器端处理,把字符串 base64, 后面的字符发送给服务器并用 Base64 解码就可以得到原始文件的二进制内容。
回调
上面的代码还演示了 JavaScript 的一个重要的特性,就是单线程执行模式。在 JavaScript 中,浏览器的 JavaScript 执行引擎在执行 JavaScript 代码时,总是以单线程模式执行,也就是说,任何时候 JavaScript 代码都不可能同时有多于 1 个线程在执行。
在 JavaScript 中,执行多任务实际上都是异步调用,比如上面的代码:
reader.readAsDataURL(file);
就会发起一个异步操作来读取文件内容。因为是异步操作,所以在 JavaScript 代码中就不知道什么时候操作结束,因此需要先设置一个回调函数:
reader.onload = function(e) {
// 当文件读取完成后,自动调用此函数
};
当文件读取完成后,JavaScript 引擎将自动调用设置的回调函数。执行回调函数时,文件已经读取完毕,所以可以在回调函数内部安全地获得文件内容。
AJAX
AJAX 全称 Asynchronous JavaScript and XML,意思是用 JavaScript 执行异步网络请求。
如果仔细观察一个 Form 的提交就会发现,一旦用户点击“Submit”按钮,表单开始提交,浏览器就会刷新页面,然后在新页面里显示操作是成功了还是失败了。如果不幸由于网络太慢或者其他原因,就会得到一个 404 页面。
这就是 Web 的运作原理:一次 HTTP 请求对应一个页面。
如果要让用户留在当前页面中,同时发出新的 HTTP 请求,就必须用 JavaScript 发送这个新请求,接收到数据后,再用 JavaScript 更新页面,这样一来,用户就感觉自己仍然停留在当前页面,但是数据却可以不断地更新。
最早大规模使用 AJAX 的是 Gmail。Gmail 的页面在首次加载后,剩下的所有数据都依赖于 AJAX 来更新。
用 JavaScript 写一个完整的 AJAX 代码并不复杂,但是需要注意:AJAX 请求是异步执行的,也就是说,要通过回调函数获得响应。
在现代浏览器上写 AJAX 主要依靠 XMLHttpRequest 对象:
function success(text) {
var textarea = document.getElementById("test-response-text");
textarea.value = text;
}
function fail(code) {
var textarea = document.getElementById("test-response-text");
textarea.value = "Error code: " + code;
}
var request = new XMLHttpRequest(); // 新建 XMLHttpRequest 对象
request.onreadystatechange = function () { // 状态发生变化时,函数被回调
if (request.readyState === 4) { // 成功完成
// 判断响应结果:
if (request.status === 200) {
// 成功,通过 responseText 拿到响应的文本:
return success(request.responseText);
} else {
// 失败,根据响应码判断失败原因:
return fail(request.status);
}
} else {
// HTTP 请求还在继续……
}
};
// 发送请求:
request.open("GET", "/api/categories");
request.send();
alert("请求已发送,请等待响应……");
当创建了 XMLHttpRequest 对象后,要先设置 onreadystatechange 的回调函数。在回调函数中,通常只需通过 readyState === 4 判断请求是否完成。如果已完成,再根据 status === 200 判断是否是一个成功的响应。
XMLHttpRequest 对象的 open() 方法有 3 个参数:第一个参数指定是 GET 还是 POST;第二个参数指定 URL 地址;第三个参数指定是否使用异步,默认是 true,所以不用写。
注意,千万不要把第三个参数指定为 false,否则浏览器将停止响应,直到 AJAX 请求完成。如果这个请求耗时 10 秒,那么 10 秒内浏览器会处于“假死”状态。
最后调用 send() 方法才真正发送请求。GET 请求不需要参数,POST 请求需要把 body 部分以字符串或者 FormData 对象传进去。
安全限制
上面代码的 URL 使用的是相对路径。如果改为其它的绝对路径,肯定会报错。
这是因为浏览器的同源策略导致的。默认情况下,JavaScript 在发送 AJAX 请求时,URL 的域名必须和当前页面完全一致。
完全一致的意思是,域名要相同(www.example.com 和 example.com 不同),协议要相同(HTTP 和 HTTPS 不同),端口号要相同(默认是 :80 端口,它和 :8080 就不同)。
想要用 JavaScript 请求外域(其他网站)的 URL,大概有以下几种方式:
一是通过在同源域名下架设一个代理服务器来转发,JavaScript 负责把请求发送到代理服务器:
"/proxy?url=http://www.sina.com.cn"
代理服务器再把结果返回,这样就遵守了浏览器的同源策略。这种方式麻烦之处在于需要服务器端额外做开发。
二是使用 JSONP,它有个限制,只能用 GET 请求,并且要求返回 JavaScript。这种方式跨域实际上是利用了浏览器允许跨域引用 JavaScript 资源:
<html>
<head>
<script src="http://example.com/abc.js"></script>
…
</head>
<body>
…
</body>
</html>
JSONP 通常以函数调用的形式返回。例如,返回 JavaScript 内容如下:
foo("data");
这样一来,如果在页面中先准备好 foo() 函数,然后给页面动态加一个 <script> 节点,相当于动态读取外域的 JavaScript 资源,最后就等着接收回调了。
以 163 的股票查询 URL 为例,对于 URL:https://api.money.126.net/data/feed/0000001,1399001?callback=refreshPrice,将得到如下返回:
refreshPrice({"0000001":{"code": "0000001", … });
因此需要首先在页面中准备好回调函数:
function refreshPrice(data) {
var p = document.getElementById("test-jsonp");
p.innerHTML = "当前价格:" +
data["0000001"].name + ":" +
data["0000001"].price + ";" +
data["1399001"].name + ":" +
data["1399001"].price;
}
最后用 getPrice() 函数触发:
function getPrice() {
var
js = document.createElement("script"),
head = document.getElementsByTagName("head")[0];
js.src = "https://api.money.126.net/data/feed/0000001,1399001?callback=refreshPrice";
head.appendChild(js);
}
就完成了跨域加载数据。
CORS
如果浏览器支持 HTML5,那就可以直接使用新的跨域策略——CORS。
CORS 全称 Cross-Origin Resource Sharing,是 HTML5 规范定义的如何跨域访问资源。
了解 CORS 前,先搞明白概念:
Origin 表示本域,也就是浏览器当前页面的域。当 JavaScript 向外域(如 sina.com)发起请求后,浏览器收到响应后,首先检查 Access-Control-Allow-Origin 是否包含本域。如果是,则此次跨域请求成功;如果不是,则请求失败,JavaScript 将无法获取到响应的任何数据。用图来表示就是:
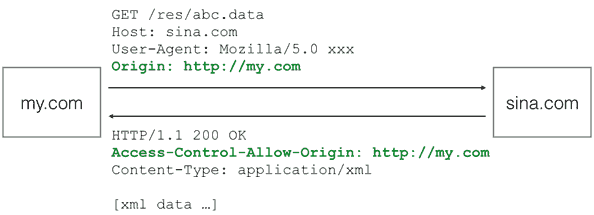
假设本域是 my.com,外域是 sina.com,只要响应头 Access-Control-Allow-Origin 为 http://my.com,或者是 *,本次请求就可以成功。
可见,跨域能否成功,取决于对方服务器是否愿意设置一个正确的 Access-Control-Allow-Origin,决定权始终在对方手中。
上面这种跨域请求,称之为“简单请求”。简单请求包括 GET、HEAD 和 POST(POST 的 Content-Type 类型仅限 application/x-www-form-urlencoded、multipart/form-data 和 text/plain),并且不能出现任何自定义头(例如 X-Custom: 12345),通常能满足多数需求。
无论是否需要用 JavaScript 通过 CORS 跨域请求资源,都要了解 CORS 的原理。最新的浏览器全面支持 HTML5。在引用外域资源时,除了 JavaScript 和 CSS 外,都要验证 CORS。例如,当引用了某个第三方 CDN 上的字体文件时:
/* CSS */
@font-face {
font-family: "FontAwesome";
src: url("http://cdn.com/fonts/fontawesome.ttf") format("truetype");
}
如果该 CDN 服务商未正确设置 Access-Control-Allow-Origin,那么浏览器无法加载字体资源。
对于 PUT、DELETE 以及其他类型如 application/json 的 POST 请求,在发送 AJAX 请求之前,浏览器会先发送一个 OPTIONS 请求(称为预检请求)到这个 URL 上,询问目标服务器是否接受:
OPTIONS /path/to/resource HTTP/1.1
Host: bar.com
Origin: http://my.com
Access-Control-Request-Method: POST
服务器必须响应并明确指出允许的 Method:
HTTP/1.1 200 OK
Access-Control-Allow-Origin: http://my.com
Access-Control-Allow-Methods: POST, GET, PUT, OPTIONS
Access-Control-Max-Age: 86400
浏览器确认服务器响应的 Access-Control-Allow-Methods 头确实包含将要发送的 AJAX 请求的 Method,才会继续发送 AJAX,否则抛出一个错误。
由于以 POST、PUT 方式传送 JSON 格式的数据在 REST 中很常见,所以要跨域正确处理 POST 和 PUT 请求,服务器端必须正确响应 OPTIONS 请求。
需要深入了解 CORS 的可查阅 W3C 文档。
Promise
在 JavaScript 的世界中,所有代码都是单线程执行的。
由于这个“缺陷”,导致 JavaScript 的所有网络操作、浏览器事件,都必须是异步执行。异步执行可以用回调函数实现:
function callback() {
console.log("Done");
}
console.log("before setTimeout()");
setTimeout(callback, 1000); // 1 秒后调用 callback() 函数
console.log("after setTimeout()");
结果如下:
before setTimeout()
after setTimeout()
// 等待 1 秒后
Done
可见,异步操作会在将来的某个时间点触发一个函数调用。
AJAX 就是典型的异步操作。以上一节的代码为例:
request.onreadystatechange = function () {
if (request.readyState === 4) {
if (request.status === 200) {
return success(request.responseText);
} else {
return fail(request.status);
}
}
};
把回调函数 success(request.responseText) 和 fail(request.status) 写到一个 AJAX 操作里很正常,但是不好看,而且不利于代码复用。
自然会想要追求更简单的写法,比如这样:
var ajax = ajaxGet("http://…");
ajax.ifSuccess(success)
.ifFail(fail);
这种链式写法的好处在于,先统一执行 AJAX 逻辑,不关心如何处理结果,然后根据结果是成功还是失败,在将来的某个时候调用 success() 函数或 fail() 函数。
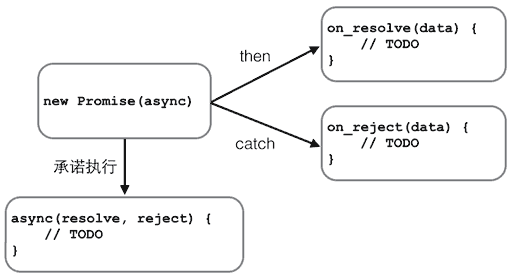
这种“承诺将来会执行”的对象在 JavaScript 中称为 Promise 对象。
先看一个最简单的 Promise 例子:生成一个 0~2 之间的随机数。如果小于 1,则等待一段时间后返回成功,否则返回失败:
function test(resolve, reject) {
var timeOut = Math.random() * 2;
log("set timeout to: " + timeOut + " seconds.");
setTimeout(function () {
if (timeOut < 1) {
log("call resolve()…");
resolve("200 OK");
} else {
log("call reject()…");
reject("timeout in " + timeOut + " seconds.");
}
}, timeOut * 1000);
}
这个 test() 函数有两个参数,这两个参数都是函数。如果执行成功,将调用 resolve("200 OK");如果执行失败,将调用 reject("timeout in " + timeOut + " seconds.")。可以看出,test() 函数只关心自身的逻辑,并不关心具体的 resolve() 和 reject() 将如何处理结果。
有了执行函数,就可以用一个 Promise 对象来执行它,并在将来某个时刻获得成功或失败的结果:
var p1 = new Promise(test);
var p2 = p1.then(function (result) {
console.log("成功:" + result);
});
var p3 = p2.catch(function (reason) {
console.log("失败:" + reason);
});
变量 p1 是一个 Promise 对象,它负责执行 test() 函数。由于 test() 函数在内部是异步执行的,当 test() 函数执行成功时,告诉 Promise 对象:
// 如果成功,执行这个函数:
p1.then(function (result) {
console.log("成功:" + result);
});
当 test() 函数执行失败时,告诉 Promise 对象:
p2.catch(function (reason) {
console.log("失败:" + reason);
});
Promise 对象可以串联起来,所以上述代码可以简化为:
new Promise(test).then(function (result) {
console.log("成功:" + result);
}).catch(function (reason) {
console.log("失败:" + reason);
});
实际测试一下,看看 Promise 是如何异步执行的:
// 清除 log:
var logging = document.getElementById("test-promise-log");
while (logging.children.length > 1) {
logging.removeChild(logging.children[logging.children.length - 1]);
}
// 输出 log 到页面:
function log(s) {
var p = document.createElement("p");
p.innerHTML = s;
logging.appendChild(p);
}
new Promise(function (resolve, reject) {
log("start new Promise…");
var timeOut = Math.random() * 2;
log("set timeout to: " + timeOut + " seconds.");
setTimeout(function () {
if (timeOut < 1) {
log("call resolve()…");
resolve("200 OK");
} else {
log("call reject()…");
reject("timeout in " + timeOut + " seconds.");
}
}, timeOut * 1000);
}).then(function (r) {
log("Done: " + r);
}).catch(function (reason) {
log("Failed: " + reason);
});
结果如下:
start new Promise…
set timeout to: 0.6643159176821918 seconds.
call resolve()…
Done: 200 OK
可见 Promise 最大的好处是在异步执行的流程中,把执行代码和处理结果的代码清晰地分离了:
Promise 还可以做更多的事情。比如,有若干个异步任务,需要先做任务 1,如果成功后再做任务 2,任何任务失败则不再继续并执行错误处理函数。
要串行执行这样的异步任务,不用 Promise 需要写一层一层的嵌套代码。有了 Promise,只需要简单地写:
job1.then(job2).then(job3).catch(handleError);
其中,job1、job2 和 job3 都是 Promise 对象。
下面的例子演示了如何串行执行一系列需要异步计算获得结果的任务:
var logging = document.getElementById("test-promise2-log");
while (logging.children.length > 1) {
logging.removeChild(logging.children[logging.children.length - 1]);
}
function log(s) {
var p = document.createElement("p");
p.innerHTML = s;
logging.appendChild(p);
}
// 0.5 秒后返回 input × input 的计算结果:
function multiply(input) {
return new Promise(function (resolve, reject) {
log("calculating " + input + " x " + input + "…");
setTimeout(resolve, 500, input * input);
});
}
// 0.5 秒后返回 input + input 的计算结果:
function add(input) {
return new Promise(function (resolve, reject) {
log("calculating " + input + " + " + input + "…");
setTimeout(resolve, 500, input + input);
});
}
var p = new Promise(function (resolve, reject) {
log("start new Promise…");
resolve(123);
});
p.then(multiply)
.then(add)
.then(multiply)
.then(add)
.then(function (result) {
log("Got value: " + result);
});
结果如下:
start new Promise…
calculating 123 x 123…
calculating 15129 + 15129…
calculating 30258 x 30258…
calculating 915546564 + 915546564…
Got value: 1831093128
setTimeout() 可以看成一个模拟网络等异步执行的函数。现在,把上一节的 AJAX 异步执行函数转换为 Promise 对象,看看用 Promise 如何简化异步处理:
// ajax() 函数将返回 Promise 对象
function ajax(method, url, data) {
var request = new XMLHttpRequest();
return new Promise(function (resolve, reject) {
request.onreadystatechange = function () {
if (request.readyState === 4) {
if (request.status === 200) {
resolve(request.responseText);
} else {
reject(request.status);
}
}
};
request.open(method, url);
request.send(data);
});
}
var log = document.getElementById("test-promise-ajax-result");
var p = ajax("GET", "/api/categories");
p.then(function (text) { // 如果 AJAX 成功,获得响应内容
log.innerText = text;
}).catch(function (status) { // 如果 AJAX 失败,获得响应代码
log.innerText = "ERROR: " + status;
});
结果如下:
{"categories":[{"id":"0013738748415562fee26e070fa4664ad926c8e30146c67000","name":"编程","tag":"tech","display_order":0,"description":"","created_at":1373874841556,"updated_at":1429763779958,"version":5},{"id":"0013738748248885ddf38d8cd1b4803aa74bcda32f853fd000","name":"读书","tag":"other","display_order":1,"description":"","created_at":1373874824888,"updated_at":1429763779974,"version":5}]}
除了串行执行若干异步任务外,Promise 还可以并行执行异步任务。
试想一个页面聊天系统,需要从两个不同的 URL 分别获得用户的个人信息和好友列表,这两个任务是可以并行执行的,用 Promise.all() 实现如下:
var p1 = new Promise(function (resolve, reject) {
setTimeout(resolve, 500, "P1");
});
var p2 = new Promise(function (resolve, reject) {
setTimeout(resolve, 600, "P2");
});
// 同时执行 p1 和 p2,并在它们都完成后执行 then():
Promise.all([p1, p2]).then(function (results) {
console.log(results); // 获得一个数组 ["P1", "P2"]
});
有些时候,多个异步任务是为了容错。比如,同时向两个 URL 读取用户的个人信息,只需要获得先返回的结果即可。这种情况下,用 Promise.race() 实现:
var p1 = new Promise(function (resolve, reject) {
setTimeout(resolve, 500, "P1");
});
var p2 = new Promise(function (resolve, reject) {
setTimeout(resolve, 600, "P2");
});
Promise.race([p1, p2]).then(function (result) {
console.log(result); // "P1"
});
由于 p1 执行较快,Promise 的 then() 将获得结果 "P1"。p2 仍在继续执行,但执行结果将被丢弃。
如果组合使用 Promise,就可以把很多异步任务以并行和串行的方式组合起来执行。
Canvas
Canvas 是 HTML5 新增的组件,它就像一块幕布,可以用 JavaScript 在上面绘制各种图表、动画等。
一个 Canvas 定义了一个指定尺寸的矩形框,在这个范围内可以随意绘制:
<canvas id="test-canvas" width="300" height="200"></canvas>
getContext("2d") 方法获得一个 CanvasRenderingContext2D 对象,所有的绘图操作都需要通过这个对象完成:
var ctx = canvas.getContext("2d");
HTML5 还有一个 WebGL 规范,允许在 Canvas 中绘制 3D 图形:
var gl = canvas.getContext("webgl");
绘制形状
可以在 Canvas 上绘制各种形状。在绘制前,需要先了解一下 Canvas 的坐标系统:
Canvas 的坐标以左上角为原点,水平向右为 X 轴,垂直向下为 Y 轴,以像素为单位,所以每个点都是非负整数。
CanvasRenderingContext2D 对象有若干方法来绘制图形:
var
canvas = document.getElementById("test-shape-canvas"),
ctx = canvas.getContext("2d");
ctx.clearRect(0, 0, 200, 200); // 擦除 (0, 0) 位置大小为 200×200 的矩形,擦除的意思是把该区域变为透明
ctx.fillStyle = "#dddddd"; // 设置颜色
ctx.fillRect(10, 10, 130, 130); // 把 (10, 10) 位置大小为 130×130 的矩形涂色
// 利用 Path 绘制复杂路径:
var path = new Path2D();
path.arc(75, 75, 50, 0, Math.PI * 2, true);
path.moveTo(110, 75);
path.arc(75, 75, 35, 0, Math.PI, false);
path.moveTo(65, 65);
path.arc(60, 65, 5, 0, Math.PI * 2, true);
path.moveTo(95, 65);
path.arc(90, 65, 5, 0, Math.PI * 2, true);
ctx.strokeStyle = "#0000ff";
ctx.stroke(path);
绘制文本
绘制文本就是在指定的位置输出文本,可以设置文本的字体、样式、阴影等,与 CSS 完全一致:
var
canvas = document.getElementById("test-text-canvas"),
ctx = canvas.getContext("2d");
ctx.clearRect(0, 0, canvas.width, canvas.height);
ctx.shadowOffsetX = 2;
ctx.shadowOffsetY = 2;
ctx.shadowBlur = 2;
ctx.shadowColor = "#666666";
ctx.font = "24px Arial";
ctx.fillStyle = "#333333";
ctx.fillText("带阴影的文字", 20, 40);
Canvas 除了能绘制基本的形状和文本,还可以实现动画、缩放、各种滤镜和像素转换等高级操作。如果要实现非常复杂的操作,考虑以下优化方案:
- 通过创建一个不可见的 Canvas 来绘图,然后将最终绘制结果复制到页面的可见 Canvas 中;
- 尽量使用整数坐标而不是浮点数;
- 可以创建多个重叠的 Canvas 绘制不同的层,而不是在一个 Canvas 中绘制非常复杂的图;
- 背景图片如果不变可以直接用
<img>标签并放到最底层。
错误处理
在执行 JavaScript 代码的时候,有些情况下会发生错误。
执行过程中,程序可能遇到无法预测的异常情况而报错。例如,网络连接中断,读取不存在的文件,没有操作权限等。对于这种错误,需要处理它,并可能需要给用户反馈。
同 Java、C# 等的异常处理机制类似,JavaScript 采用的也是 try…catch…finally 语句。基本逻辑是:
try {
// 可能出现错误的代码
} catch (e) {
// 捕获错误后的处理部分
} finally {
// 无论是否出现错误,最终都会执行的代码
}
其中,catch 和 finally 都是可选的。这就意味着存在三种形式的 try 声明:
try…catchtry…finallytry…catch…finally
需要注意的是,根据规范,该语句块中只有一个 catch 子句,对于错误类型的判断则转交给 catch 子句体内部,而不是像 Java、C# 等那样的使用多个 catch 子句组成条件 catch 子句。
try {
myroutine(); // 可能抛出多种错误
} catch (e) {
if (e instanceof TypeError) {
// 处理 TypeError 错误的语句
} else if (e instanceof RangeError) {
// 处理 RangeError 错误的语句
} else if (e instanceof EvalError) {
// 处理 EvalError 错误的语句
} else {
// 处理任何未指定的错误的语句
logMyErrors(e); // 将错误对象传递给错误处理程序
}
}
程序也可以主动抛出一个错误,让执行流程直接跳转到 catch 块。抛出错误使用 throw 语句。示例如下:
var r, n, s;
try {
s = prompt("请输入一个数字");
n = parseInt(s);
if (isNaN(n)) {
throw new Error("输入错误");
}
r = n * n; // 计算平方
console.log(n + " 的平方等于 " + r);
} catch (e) {
console.log("出错了:" + e);
}
此外,由于错误是层层抛出的,所以不必在每一个函数内部捕获错误,只需要在合适的地方来个统一捕获、集中处理。